Scraping Engine
Description
The scripting engine requests files which it then parses, manipulates, and/or stores according to user defined processes. It is the heart of screen-scraper and has been optimized at all points of development to be as efficient as possible. It is made up of multiple parts which can be manipulated using the workbench:
- Scraping Sessions: Series of scrapeable files, that screen-scraper will request in a designated sequence. It may also contain calls to scripts.
- Scrapeable Files: File interaction (usually a webpage) that can be called from a scraping session or script. They may contain variables for file location or url parameters (GET or POST).
- Extractor Patterns: Snippits used to gather information from scrapeable files. They contain any number of extractor tokens.
- Extractor Tokens: Named regular expression matches used to indicate what information from the extractor pattern to make available to subsequent scripts and scrapeable files.
- Scripts: User defined custom scripts that process the information gathered in the progression of the scrape.
The rest of this section contains information about using screen-scraper, through the workbench, to achieve different goals. These can be difficult to understand without some exposure to the software. That is why we would like to encourage you to go through our first few tutorials before continuing.
Adding Java Libraries
Overview
screen-scraper allows for Java libraries to be added to the classpath. Simply copy any jar files you'd like to reference into the lib\ext folder found in screen-scraper's directory. The next time you start up screen-scraper it will automatically add the jar files to its classpath. Note that you'll still need to use the import statement within your scripts to refer to specific classes:
import com.foo.bar.*;
screen-scraper was built on a Java 1.5 platform. Your Java scripts must accept at least a version 1.5 JRE in order to compile and run properly.
Anonymization
Overview
Under certain circumstances you may want to anonymize your scraping so that the target site is unable to trace back your IP address. For example, this might be desirable if you're scraping a competitor's site, or if the web site blocks IP addresses that make too many requests.
There are a few different ways to go about this using screen-scraper:
If you choose to run anonymous scripts from an external script, it is valuable to read through the documentation on controlling anonymization externally.
Aside from the above methods, you might find our blog posting on how to surf and screen-scrape anonymously helpful. It's slightly dated, but still very relevant.
Automatic Anonymization
Overview
The screen-scraper automatic anonymization service works by sending each HTTP request made in a scraping session through a separate high-speed HTTP proxy server. The end effect of this is that the site you're scraping will see any request you make as coming from one of several different IP addresses, rather than your actual IP address. These HTTP proxy servers are actually virtual machines that get spawned and terminated as you need them. You'll use screen-scraper to either manually or automatically spawn and terminate the proxy servers.
Steps to take
- Request an Anonymization account
- Pay set up fee
- Enter your anonymization password
- Check the "anonymize this scraping session" checkbox
- Run your scraping session
Cost
- $150 setup
- 25 cents per proxy per hour
Note: When using the automatic anonymization method, while the remote web site may not be able to determine your IP address, your activity will still be logged. If you attempt to use the proxy service for any illegal activities, the chances are very good that you will be prosecuted.
Limitations
While the automatic anonymization service provides an excellent way to cloak your IP address it is still possible that the target web site will block enough of the anonymized IP addresses that the anonymization could fail. Unfortunately we can't make any guarantees that you won't get blocked; however, by using the automatic anonymization service the chances of getting blocked are reduced dramatically.
Miscellaneous
- Anonymization REST Interface
- Workbench Interface: Scraping Session: Anonymization tab
- AnonymousProxyPassword: The password that you were sent.
- AnonymousProxyAllowedIPs: The IP addresses permitted to access anonymous sessions.
- AnonymousProxyMaxRunning: Maximum number of proxy servers used to do the scrape.
- AnonymizationURLPrepend: Which server to use for anonymization. By default http://anon.screen-scraper.com will be used.
Acceptable values are http://anon.screen-scraper.com and http://anon2.screen-scraper.com.
Automatic Anonymization: Setup
Controlling your Account
The anonymous proxy servers will be set up in such a way that they only allow connections from your IP address. This way no one else can use any of the proxies without your authorization. This configuration is tied to your password. For more on restricting connections see documentation on managing the screen-scraper server.
If you'll be running your anonymized scraping sessions on the same machine (or local network) you're currently on and you are using the workbench, you can click the Get the IP address for this computer button to determine your current IP address.
screen-scraper Setup
Using Workbench
Anonymization settings can be configured using screen-scraper's workbench. Settings are determined in the anonymous proxy settings of the settings dialog box.
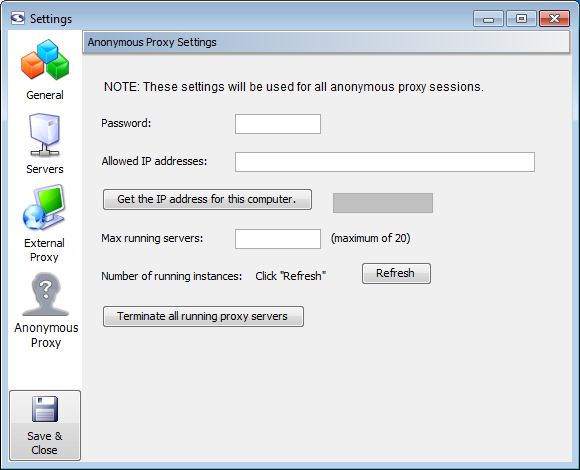
When you sign up for the anonymization service you'll be given the password that allows your instance of screen-scraper to manage anonymous proxies for you. You'll enter it into the Password textbox in the settings.
As the proxy servers get spawned and terminated, it's a good idea to establish the maximum number of running proxy servers you'd like to allow. This is done via the Max running servers setting. Because you pay for proxy servers by the hour, if you don't have your scraping session set up to automatically shut them down at the end, you'll use the Terminate all running proxy servers button in order to do that.
We find that as many as 10 proxy servers but no fewer than five are adequate for most situations.
Using screen-scraper.properties File
If you're setting this value in a GUI-less environment (i.e., a server with no graphical interface), you'll want to set these values in the resource/conf/screen-scraper.properties file (if these property is not already in the file you'll want to add it).
Be sure to modify the resource/conf/screen-scraper.properties file only when screen-scraper is not running.
Scraping Session Setup
Aside from these global settings, there are a few settings that apply to each scraping session you'd like to anonymize. You can edit these settings under the anoymization tab of your scraping session.
Once you've configured all of the necessary settings, try running your scraping session to test it out. You'll see messages in the log that indicate what proxy servers are being used, how many have been spawned, etc.
As your anonymous scraping session runs, you'll notice that screen-scraper will automatically regulate the pool of proxy servers. For example, if screen-scraper gets a timed out connection or a 403 response (authorization denied), it will terminate the current proxy server, and automatically spawn a new one in its place. This way you will likely always have a complete set of proxy servers, regardless of how frequently the target web site might be blocking your requests. You can also manually report a proxy server as blocked by calling session.currentProxyServerIsBad() in a script. When this method is called the current proxy server will be shut down and replaced by another.
Anonymization via Manual Proxy Pools
Overview
If the automatic anonymization method isn't right for you, the next best alternative might be to manually handle working with screen-scraper's built-in ProxyServerPool object. The basic approach involves running a script at the beginning of your scraping session that sets up the pool, then calling session.currentProxyServerIsBad() as you find that proxy servers are getting blocked. In order to use a proxy pool, you'll also need to get a list of anonymous proxy servers. Generally you can find these by Googling around a bit.
See available methods:
ProxyServerPool
Anonymization API
Example
// Create a new ProxyServerPool object. This object will
// control how screen-scraper interacts with proxy servers.
proxyServerPool = new ProxyServerPool();
// We give the current scraping session a reference to
// the proxy pool. This step should ideally be done right
// after the object is created (as in the previous step).
session.setProxyServerPool( proxyServerPool );
// This tells the pool to populate itself from a file
// containing a list of proxy servers. The format is very
// simple--you should have a proxy server on each line of
// the file, with the host separated from the port by a colon.
// For example:
// one.proxy.com:8888
// two.proxy.com:3128
// 29.283.928.10:8080
// But obviously without the slashes at the beginning.
proxyServerPool.populateFromFile( "proxies.txt" );
// screen-scraper can iterate through all of the proxies to
// ensure theyre responsive. This can be a time-consuming
// process unless it's done in a multi-threaded fashion.
// This method call tells screen-scraper to validate up to
// 25 proxies at a time.
proxyServerPool.setNumProxiesToValidateConcurrently( 25 );
// This method call tells screen-scraper to filter the list of
// proxy servers using 7 seconds as a timeout value. That is,
// if a server doesnt respond within 7 seconds, it's deemed
// to be invalid.
proxyServerPool.filter( 7 );
// Once filtering is done, it's often helpful to write the good
// set of proxies out to a file. That way you may not have to
// filter again the next time.
proxyServerPool.writeProxyPoolToFile( "good_proxies.txt" );
// You might also want to write out the list of proxy servers
// to screen-scraper's log.
proxyServerPool.outputProxyServersToLog();
// This is the switch that tells the scraping session to make
// use of the proxy servers. Note that this can be turned on
// and off during the course of the scrape. You may want to
// anonymize some pages, but not others.
session.setUseProxyFromPool( true );
// Check number of available proxies
if (proxyServerPool.getNumProxyServers() < 4)
{
// As a scrapiing session runs, screen-scraper will filter out
// proxies that become non-responsive. If the number of proxies
// gets down to a specified level, screen-scraper can repopulate
// itself. Thats what this method call controls.
proxyServerPool.setRepopulateThreshold( 5 );
}
That's about all there is to it. Aside from occasionally calling session.currentProxyServerIsBad(), you may also want to call session.setUseProxyFromPool to turn anonymization on and off within the scraping sesison.
Mapping Extracted Data
The web interface is only available for enterprise edition users of screen-scraper.
Overview
The mapping tab allows you to alter extracted values. Often once you extract data from a web page you need to put it into a consistent format. For example, you may want products with very similar names to have identical names.
screen-scraper makes use of mapping sets when determining how to map a given extracted value. A mapping set may contain any number of mappings, which screen-scraper will analyze in sequence until it finds a match, or runs out of mappings. As such, you'll often want to put more specific mappings higher in sequence than more general mappings.
Example
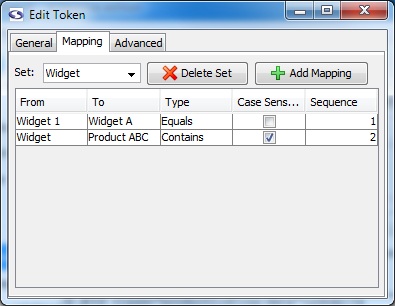
Consider the screen-shot of the mapping tab: if the extracted value were Widget 123 screen-scraper would first try to match using the Widget 1 mapping. Because this is an equals match the mapping wouldn't occur, so screen-scraper would proceed to the second mapping. The second mapping would match because a contains type was designated. That is, the text Widget 123 contains the text Widget. As such, the extracted data Widget 123 would become Product ABC, because that is the To value designated for the second mapping.
Using Regular Expressions
When using regular expressions in your mapping you can also make use of back references. Back references allow you to preserve values in the original text when mapped to the To value. For example, if you were mapping the value Widget 123 you could use the regular expression Widget (\d*). In the To column you could then enter the value Product \1, which, when mapped, would convert Widget 123 to Product 123. The value in parentheses in the From column gets inserted via the \1 marker found in the To column.
Running Scraping Sessions within Scraping Sessions
Overview
This feature is only available to Professional and Enterprise editions of screen-scraper.
It is possible to run a scraping session within a scraping session that is already running. This is done with the RunnableScrapingSession class. Detailed documentation on methods available for the RunnableScrapingSession class are available in our API documentation. Here's a specific example of how the RunnableScrapingSession might be used in a screen-scraper script:
// Generate a new RunnableScrapingSession object that will inherit
// from the current scraping session. This object will be used
// to run the scraping session "My Scraping Session"
myRunnableScrapingSession = new RunnableScrapingSession( "My Session", session );
// Because we passed the "session" object to the RunnableScrapingSession
// it will have access to all of the session variables within the
// currently running session. As such, there's no need to explicitly
// set any new session variables. We simply tell it to scrape.<
myRunnableScrapingSession.scrape();
// Once it's done scraping, because it inherited from our currently
// running scraping session, we have access to any session variables
// that were set when the RunnableScrapingSession ran in the context
// of our currently running scraping session. For example, let's
// suppose that when the RunnableScrapingSession ran it set a new
// variable called "MY_VAR". Because of the inheritance, we could
// do something like this to see th new value:<
session.log( "MY_VAR: " + session.getVariable( "MY_VAR" ) );
Script Overwriting
Overview
Scripts attached to a scraping session are exported along with it. When you subsequently import that scraping session into another instance of screen-scraper it might overwrite existing scripts in that instance. In some cases, though, you might have a series of general scripts shared by many scraping sessions. In these cases you often want to ensure that the very latest versions of these general scripts get retained in a given instance.
Using the Workbench
In the main pane of the script there is a Overwrite this script on import checkbox. When checked, any name clashes between existing scripts and imported versions will prompt you whether it should overwrite the script or not. If the local version's Overwrite this script on import checkbox is unchecked this file will not be overwritten even if you click to have it overwritten.
In a GUI-less environment
Checking the Overwrite this script on import requires access to the screen-scraper workbench, which you may not have access to if screen-scraper is running in a GUI-less environment. In these cases you can make use of the ForceOverwriteScripts property in the resource/conf/screen-scraper.properties file to allow scripts that have this box un-checked to be overwritten. In order to overwrite scripts that have this checkbox un-checked in a GUI-less environment you would follow these steps:
- Stop screen-scraper (or ensure that it isn't currently running).
- Open the resource/conf/screen-scraper.properties file.
- Add this line to the properties file: ForceOverwriteScripts=true (or edit the line, if it already exists).
- Save and close the properties file.
- Start up screen-scraper and import the scraping sessions or scripts.
Once you're finished importing you may want to stop screen-scraper, set the property back to false, then start up again. Note that when you import scripts with the ForceOverwriteScripts property set to true screen-scraper will import the scripts regardless of whether or not the Overwrite this script on import checkbox is checked.
Using Extractor Patterns
Overview
Extractor patterns allow you to pinpoint select snippets of data that you want extracted from a web page. It is a block of text (usually HTML) that contains special tokens that will match pieces of data you're interested in extracting. These tokens are text labels surrounded by the delimiters ~@ and @~ (e.g. ~@NAME@~). The identifier between the delimiters can contain only alpha-numeric characters and underscores.
Extractor patterns are added to scrapeable files under the extractor patterns tab.
You can think of an extractor pattern like a stencil. A stencil is an image in cut-out form, often made of thin cardboard. As you place a stencil over a piece of paper, apply paint to it, then remove the stencil, the paint remains only where there were holes in the stencil. Analogously, you can think of placing an extractor pattern over the HTML of a web page. The tokens correspond to the holes where the paint would pass through. After an extractor pattern is applied it reveals only the portions of the web page you'd like to extract.
Extractor tokens designate regions where data elements are to be captured. For example, given the following HTML snippet:
you would extract piece of text by creating an extractor pattern with a token positioned like so:
The extracted text could then be accessed via the identifier EXTRACTED_TEXT.
If you haven't done so already, we'd recommend going through our first tutorial to get a better feel for using extractor patterns.
Tips/Suggestions
- Test your patterns frequently. Extractor patterns take some practice. Especially when you're first trying them out you'll want to test them as you're working with them. It often helps to test it after every couple of tokens you insert.
- Use regular expressions to make your extractor patterns more precise. One of the most common problems encountered occurs when an extractor pattern matches too much data, which usually includes a lot of HTML. There are a couple of ways to address this problem. One is to extend the pattern outward. That is, include HTML that falls before and after the block you're trying to match. The second approach, which is generally the easier of the two, is to include regular expressions. We've included a number of common regular expressions that you can select from the drop-down list. In general, if you can use more precise regular expressions you can reduce the amount of HTML in the extractor pattern. Doing so makes your patterns more resilient to changes that might be made to the web site you're scraping.
If an extractor pattern takes too long to match a block of text it will timeout. The timeout setting may be adjusted from the general tab of the Settings located in the menu. If you find that your extractor pattern is timing out you might try adjusting it by using more precise regular expressions.
- Ensure that the pattern extracts the number of data records you expect it to. Oftentimes your pattern might not be as flexible as you think it is. Test it out to make sure it matches as many times as you think it should.
- Try tidying the HTML. This will ensure that white space is handled consistently and will often clean up extraneous characters. The setting that determines whether or not HTML gets tidied is adjusted under the advanced tab of the scrapeable file.
Using Scripts
Overview
screen-scraper's scraping engine allows you to associate custom scripts with various events in the scraping process. It is recommended that you read about managing and scripting in screen-scraper before continuing.
Using the scripts
Depending on what event triggers a script to be run different objects will be in-scope. Triggers regarding the scraping session are added on the general tab of the scraping session, file request/response triggers are associated on the properties tab of the scrapeable file, and extractor pattern events in the scripts section of the main tab in the extractor patterns tab of the scrapeable file.
Scripts can also be used to run scripts using the session.executeScript method.
Built-in objects
screen-scraper offers a few objects that you can work with in a script in the scraping engine. See the variable scope section and/or API documentation for more details.
- session: The running scraping session.
- scrapeableFile: The file interaction including request and response, it also holds the extractor pattern requests.
- dataSet: All of the matches from an extractor pattern's tokens.
- dataRecord: A single match of an extractor pattern's tokens.
Variable scope
Depending on when a script gets run different variables may be in or out of scope. When associating a script with an object, such as a scraping session or scrapeable file, you're asked to specify when the script is to be run. The table that follows specifies what variables will be in scope depending on when a given script is run. Only variables that are in scope are accessible to the script.
| When Script is Run | session in scope | scrapeableFile in scope | dataSet in scope | dataRecord in scope |
| Before scraping session begins | X | |||
| After scraping session ends | X | |||
| Before file is scraped | X | X | ||
| After file is scraped | X | X | ||
| Before pattern is applied | X | X | ||
| After pattern is applied | X | X | X | |
| Once if pattern matches | X | X | X | X |
| Once if no matches | X | X | ||
| After each pattern match | X | X | X | X |
Debugging scripts
One of the best ways to fix errors is to simply watch the scraping session log and the error.log file (located in the log directory where screen-scraper was installed) for script errors. When a problem arises in executing a script screen-scraper will output a series of error-related statements to the logs. Often a good approach in debugging is to build your script bit by bit, running it frequently to ensure that it runs without errors as you add each piece.
When screen-scraper is running as a server it will automatically generate individual log files in the log directory for each running scraping session (this can be disabled in the settings window). An error.log file will also be generated in that same directory when internal screen-scraper errors occur.
The breakpoint window can also be invaluable in debugging scripts. You can invoke it by inserting the line session.breakpoint() into your script.
Using Session Variables
Overview
Session variables allow you store values that will persist across the life of a scraping session.
Setting session variables
There are a few different ways to set session variables.
- Within a script using the setVariable method of the session object
- Designate that the value matched by a extractor token should be saved in a session variable (check Save in session variable in the main tab of the extractor token).
- Using the RemoteScrapingSession object from external sources (such as a PHP or ASP script) via their setVariable methods (see scripting in screen-scraper for more details).
Retrieving values from session variables
As with setting session variables, there is more than one way to retrieve values of session variables.
- Within a script using the getVariable method of the session object.
- Embed the identifier for the session variable, surrounded by ~# and #~ delimiters.
If you have a session variable identified by QUERY_PARAM you might embed it into the URL field of a scrapeable file using http://www.mydomain.com/myscript.php?query=~#QUERY_PARAM#~. screen-scraper will automatically replace the ~#QUERY_PARAM#~ with the value of the session variable.
Using Sub-Extractor Patterns
Overview
Sub-extractor patterns allow you to extract data in the context of an extractor pattern, providing significantly more flexibility in pinpointing the specific pieces you're after. Consider a search results page consisting of rows and columns of data. Using normal extractor patterns you would use a single pattern to extract the data from all columns for a single row. In many cases this works just fine; however, the process gets more complicated when each row differs significantly. For example, certain cell rows may be in different colors or their contents may be completely missing. With a normal extractor pattern it would be difficult to account for the variability in the cells. By using sub-extractor patterns you could create a normal extractor pattern to extract an entire row, then use individual sub-extractor patterns to pull out the individual cells.
When using sub-extractor patterns only the first match will be used. That is, even if a sub-extractor pattern could match multiple times, only the data corresponding to the first match will be extracted. Because of this sub-extractor patterns are not always the correct method for getting data within a larger context. To get multiple matches in a larger context, like all rows in a table, you would instead use manual extractor patterns.
Example
Consider the following HTML table:
| Name | Phone | Address |
|---|---|---|
| Juan Ferrero | 111-222-3333 | 123 Elm St. |
| Joe Bloggs | No contact information available | |
| Sherry Lloyd | 234-5678 (needs area code) | 456 Maple Rd. |
Here is the corresponding HTML source:
<tr>
<th>Name</th>
<th>Phone</th>
<th>Address</th>
</tr>
<tr>
<td class="Name">Juan Ferrero</td>
<td class="Phone">111-222-3333</td>
<td class="Address">123 Elm St.</td>
</tr>
<tr class="even">
<td class="Name">Joe Bloggs</td>
<td colspan="2">No contact information available</td>
</tr>
<tr>
<td class="Name">Sherry Lloyd</td>
<td class="Phone warning">234-5678 (needs area code)</td>
<td class="Address">456 Maple Rd.</td>
</tr>
</table>
It would be difficult to write a single extractor pattern that would extract the information for each row because the contents of the cells differ so significantly. The different colored cells and the cell spanning two columns make the data too inconsistent to be easily extracted using a single pattern (which would require lots of regular expressions and might still prove impossible or inconsistent).
Consider this extractor pattern:
The ~@DATARECORD@~ extractor pattern token is special in that it defines the block of data to which you wish to apply sub-extractor patterns. Sub-extractor patterns cannot be applied to a token with a name other than DATARECORD
If applied to the HTML above the extractor pattern would produce the following three matches:
2. class="even"><td class="Name">Joe Bloggs</td><td colspan="2">No contact information available</td>
3. ><td class="Name">Sherry Lloyd</td><td class="Phone warning">234-5678 (needs area code)</td><td class="Address">456 Maple Rd.</td>
Sub-extractor patterns would allow you to extract individual pieces of information from each row. For example, consider this sub-extractor pattern:
If applied to each of the individual extracted rows above the following three pieces of information would be extracted:
2. Joe Bloggs
3. Sherry Lloyd
This is a simple case. Now consider the extractor pattern for the phone number:
If applied to each of the individual extracted rows above the following three pieces of information would be extracted:
2.
3.
In the case of Sherry Lloyd this presents a serious problem because she does have a phone number listed. It is not selected because of the additional class. Let's adjust the sub-extractor pattern slightly:
The ~@nondoublequotes@~ represents an extractor token that uses the Non-double quotes regular expression: [^"]*. Matching anything between where it is covering until it encounters double quotes. In this particular case Sherry's phone number also gets extracted.
We now have the case of the cell in the second row that spans two columns, which would not get extracted by our current sub-extractor patterns. We may still want this information, however, so we create the following sub-extractor pattern, just in case the cell exists:
If applied to our data we'd get the following results:
2. No contact information available
3.
When multiple sub-extractor patterns hold a token with the same name (in this case, PHONE), the last one to match is the one that determines the value of the token. In this example either one or the other will match. If both could match then we would want to have the first phone extractor pattern ordered later than the one to match the no-data-available pattern
Sub-extractor patterns aggregate everything that's extracted into a single data set. Using all of our extractor and sub-extractor patterns together we'd get the following data set:
| Data record # | Name | Phone |
|---|---|---|
| Data record #1 | Juan Ferrero | 111-222-3333 |
| Data record #2 | Joe Bloggs | No contact information available |
| Data record #3 | Sherry Lloyd | 234-5678 (needs area code) |
Important Notes
- When two sub-extractor patterns hold a token with the same name, the one that doesn't match anything will have no effect. Sub-extractor patterns are applied in sequence, and those that match something will take precedence over those that don't.
- ~@DATARECORD@~ is the extractor token identifier that defines the block of data to which you wish to apply sub-extractor patterns. You cannot use sub-extractor patterns without using this token name in the main extractor pattern.
- When using sub-extractor patterns only the first match will be used. That is, even if it could match multiple times, only the data corresponding to the first match will be extracted.