Scrapeable Files
Overview
A scrapeable file is a URL-accessible file that you want to have retrieved as part of a scraping session. These files are the core of screen-scraping as they determine what files will be available to extract data from.
In addition to working with files on remote servers, screen-scraper can also handle files on local file systems. For example, the following is a valid path to designate in the URL field: C:\wwwroot\myweb\my_file.htm.
Managing Scrapeable Files
Adding
- Click the Add Scrapeable File button on the general tab of the desired scraping session.
- Right click on the desired scraping session in the objects tree and select Add Scrapeable File.
Removing
- Press the Delete key when it is selected in the objects tree
- Right-click on the desired scrapeable file and select Delete.
- Click the Delete button in the properties tab of the scrapeable file.
Scrapeable File: Properties tab
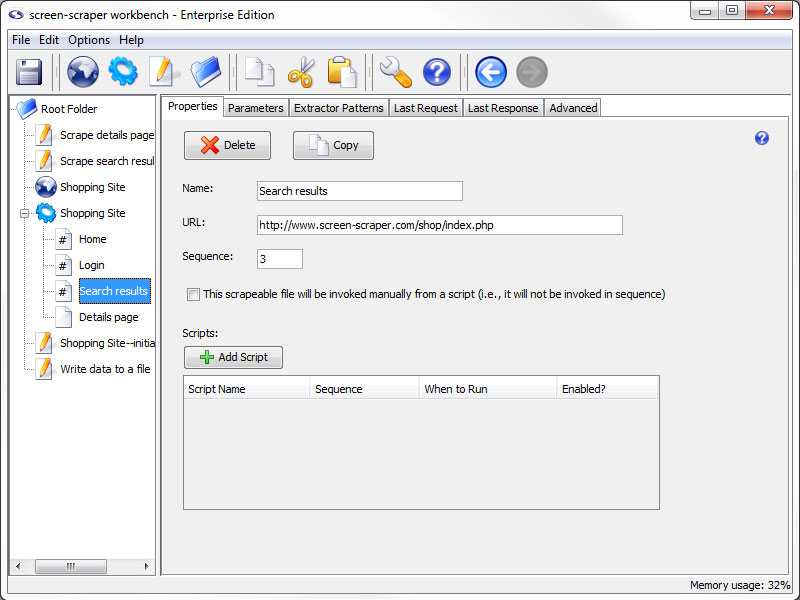
Properties Tab
- Delete: Deletes the scrapeable file.
- Copy (professional and enterprise editions only): Copies the scrapeable file.
- Name: Identifies the scrapeable file.
- URL: The URL of the file to be scraped. This is likely something like http://www.mysite.com/, but can also contain embedded session variables, like this: http://www.mysite.com/cgi-bin/test.cgi?param1=~#TEST#~. In the latter case the text ~#TEST#~ would get replaced with the value of the session variable TEST.
- Sequence: Indicates the order in which the scraping session will request this file.
- This scrapeable file will be invoked manually from a script: Indicates that this scrapeable file will be invoked within a script, so it should not be scraped in sequence. If this box is checked the Sequence text box becomes grayed out.
You can tell what files are being scraped manually and which are in sequence using the objects tree. Sequenced scrapeable files are displayed with a pound sign (#) on them.
- Scripts: All of the scripts associated with the scrapeable file.
- Add Script: Adds a script association to direct and manipulate the flow of the scrapeable file.
- Script Name: Specifies which script should be run.
- Sequence: The order in which the scripts should be run.
- When to Run: When the scrapeable file should run the script.
- Enabled: A flag to determine which scripts should be run and which shouldn't be.
Scrapeable File: Parameters tab
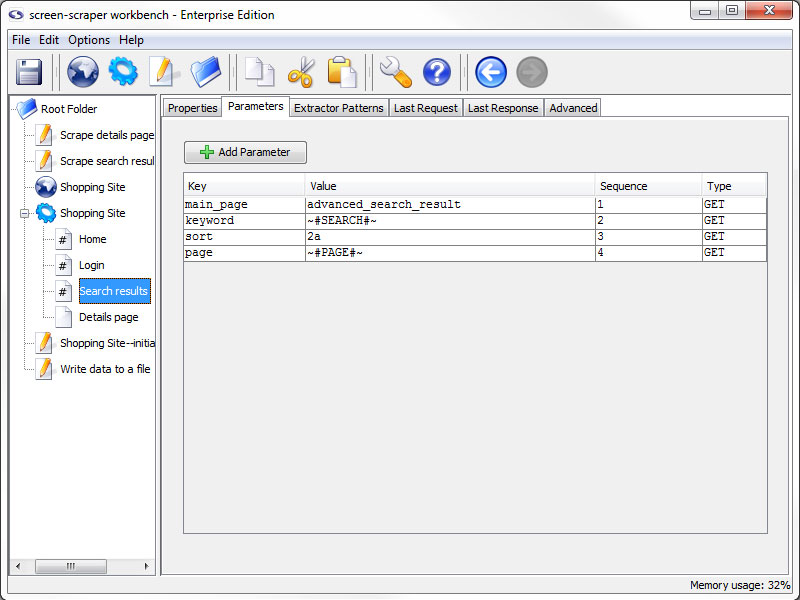
Parameters Tab
- Add Parameter: Adds a parameter to scrapeable file request.
- Key: The name of the parameter.
- Value: The value to be associated with the parameter.
- Sequence: Order in which the parameters appear on the request strings.
- Type: Indicates if the parameter should be sent using a GET or POST method when the file is requested.
GET parameters can also be embedded in the URL field under the Properties tab.
Parameters can be deleted by selecting them and either hitting the Delete key on the keyboard, or by right-clicking and selecting Delete.
Using Session Variables
Session variables can be used in the Key and Value fields. For example, if you have a POST parameter, username, you might embed a USERNAME session variable in the Value field with the token ~#USERNAME#~. This would cause the value of the USERNAME session variable to be substituted in place of the token at run time.
Upload a File (enterprise edition only)
In the enterprise edition of screen-scraper you can also designate files to be uploaded. This is done by designating FILE as the parameter type. The Key column would contain the name of the parameter (as found in the corresponding HTML form), and the value would be the local path to the file you'd like to upload (e.g., C:\myfiles\this_file.txt).
Scrapeable File: Extractor Patterns tab
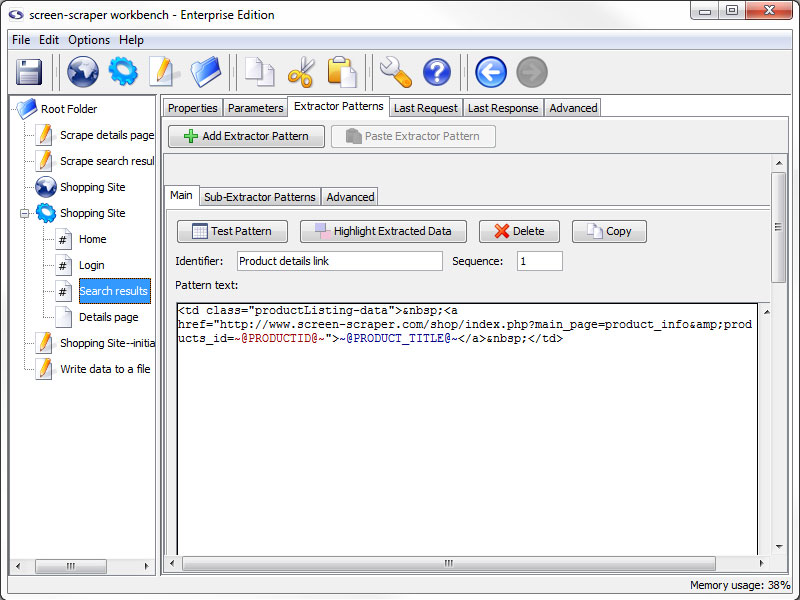
Extractor Patterns Tab
- Add Extractor Pattern: Add a blank extractor pattern to the scrapeable file.
- Paste Extractor Pattern (professional and enterprise editions only): Creates a new extractor pattern from a previously copied one.
This button is grayed out if there is not a extractor pattern currently copied.
This tab holds the various extractor patterns that will be applied to the HTML of this scrapeable file. The inner frame will be discussed in more detail when discussing them.
Scrapeable File: Last Request tab
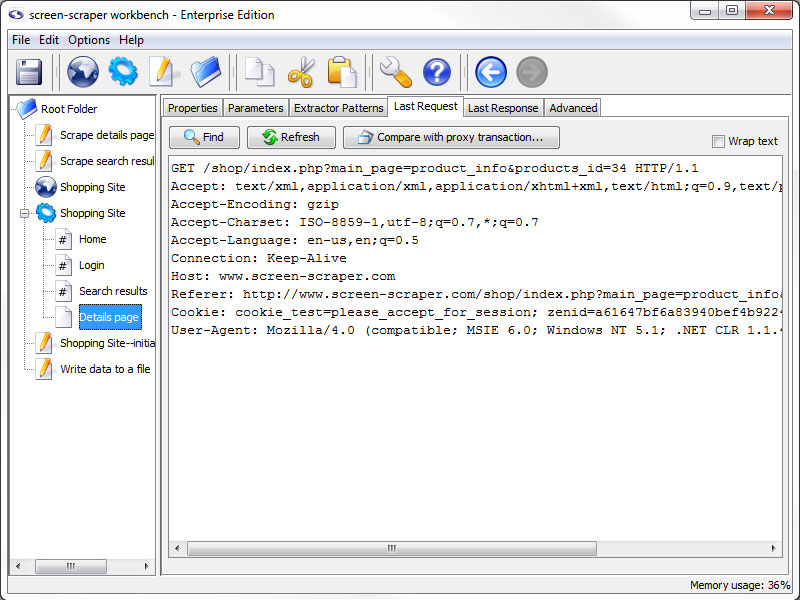
Last Request Tab
- Refresh: Requests the newest version of the last requested file.
- Compare with proxy transaction (professional and enterprise editions only): Open a Compare Last Request and Proxy Transaction window, allowing you to compare the last request of the scrapeable file with a proxy session HTTP Transaction request.
This can be very helpful for pages that are very specific on request settings or where you are getting unexpected results from the page. This is the best place to start when you experience this type of issue.
This tab will display the raw HTTP request for the last time this file was retrieved. This tab can be useful for debugging and looking at POST and GET parameters that were sent to the server.
Scrapeable File: Last Response tab
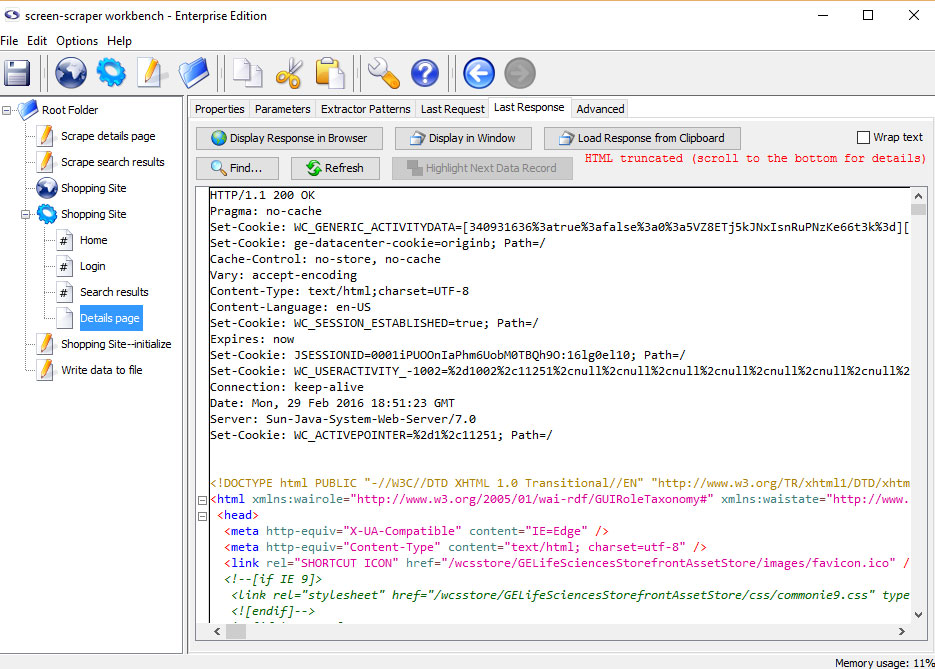
Last Response Tab
- Display Response in Browser: Displays the web page in your default web browser.
- Find: Search the source code for a string of text.
- Refresh: Reload display with the most recent response.
- Load Response from Clipboard: Loads an html response from the clipboard.
The contents shown under the this tab might appear differently from the original HTML of the page. screen-scraper has the
ability to tidy the HTML, which is done to facilitate data extraction. See using extractor patterns for more details.
Creating Extractor Patterns from Last Response
The most common use for this tab is in generating and testing extractor patterns. You can generate
an extractor patterns by highlighting a block of text or HTML, right-clicking and selecting
Generate extractor pattern from selected text.
Scrapeable File: Advanced tab
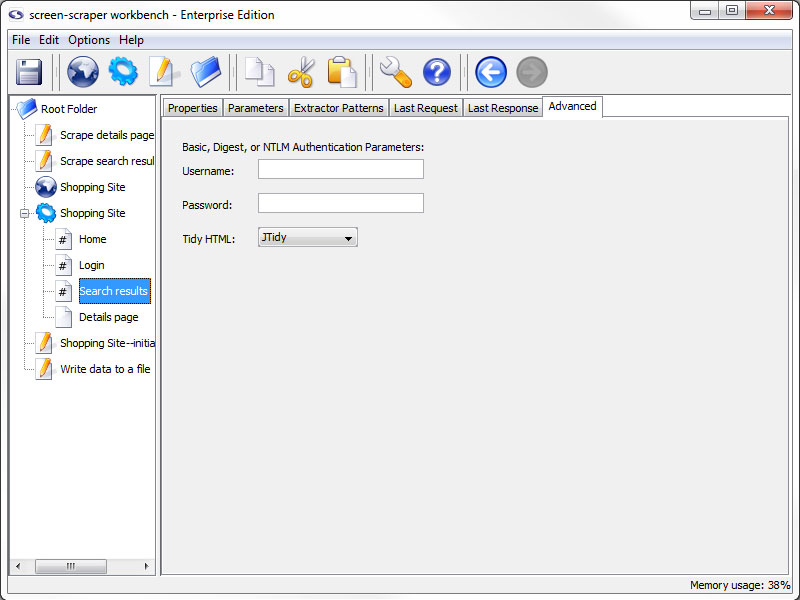
Advanced Tab (professional and enterprise editions only)
- Username and Password (professional and enterprise editions only): These two text fields are used with sites that make use of Basic, Digest, NTLM authentication.
You can generally recognize when a web site requires this type of authentication because, after requesting the page, a small box will pop up requesting a username and password.
- Tidy HTML (professional and enterprise editions only): Which tidier screen-scraper should use to tidy the HTML after requesting the file. This cleans up the HTML, which facilitates extracting data from it.
A minor performance hit is incurred, however, when tidying. In cases where performance is critical Don't Tidy HTML should be selected.