6: Page Scraping Script
Page Scraping Script Explanation
For each details link we're going to scrape the corresponding details page. This is a common scenario in screen-scraping: given a search results page, you need to extract details for each product, which means following each of the product details links. For each details page you'll likely want to extract out pieces of information corresponding to the products.
Details Scrapeable File
Let's start by creating a scrapeable file for the details page. We could create it from the proxy session; but, because it's pretty simple, let's just create it from scratch.
Click on the Shopping Site scraping session, then the General tab, then the Add Scrapeable File button.
Give the scrapeable file the name Details page, and the following URL:
You'll notice that this time we're leaving all of the parameters embedded in the URL. Sometimes with shorter URL's it's more convenient to take this approach rather than breaking them out under the Parameters tab.
As before, when the scraping session runs, the PRODUCTID token will be replaced by the value of the PRODUCTID session variable.
At this point, click the This scrapeable file will be invoked manually from a script checkbox. If we didn't do this, screen-scraper would invoke this scrapeable file in sequence (after the search results page), which we don't want. Instead, we're going to tell screen-scraper to invoke this scrapeable file from a script.
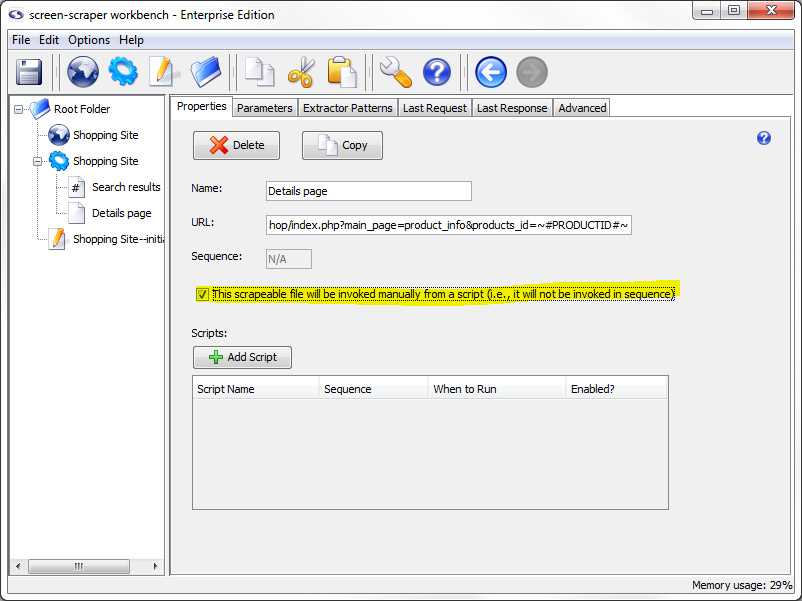
You might have noticed that by checking the This scrapeable file will be invoked manually from a script checkbox the symbol of the scrapeable file changed from (sequenced scrapeable file) to (non-sequenced scrapeable file. This change will cause the non-sequenced file to move to the bottom of the scrapeable files and be sorted alphabetically with other non-sequenced scrapeable files.
Write Script
First, create a new script and call it Scrape details page, then enter the following code in the Script Text
session.scrapeFile( "Details page" );
Adding Details Script Association
OK, this is where we need to take a moment to think: for each product ID our Product details link extractor pattern extracts, we want to scrape the product details page using the corresponding PRODUCTID. So the script needs to run after each time the pattern matches.
To add the association, go to the Product details link extractor pattern by clicking the Search results scrapeable file, then the Extractor Patterns tab. Notice the Scripts section under the extractor pattern. Click the Add Script button to add a script association. In the Script Name column, if it isn't already selected, select our Scrape details page script and under the When to Run column, select After each pattern match.
Let's walk through that a bit more slowly. After the search results page is requested the Product details link will be applied to the HTML in the page. Remember that this particular extractor pattern will match 10 times: once for each product details link. Each time it matches it will grab a different product ID and save the value of that product ID into the PRODUCTID session variable. The Scrape details page script will get invoked after each of these matches, and each time the PRODUCTID session variable will hold a different product ID. As such, when the Details page gets scraped the URL will get a different product. For example, the first time the extractor pattern matches the PRODUCTID session variable will hold "8", and the URL will be:
But, the next time, the product ID will be 34 and the URL will be:
If it helps, think again about the spreadsheet analogy. You can imagine screen-scraper walking through each row in the spreadsheet. It encounters a row, saves any needed data in session variables (the product ID, in this case), then invokes the Scrape details page script. Because it just matched a specific product ID, and saved its value in a session variable, when the Details page scrapeable file gets invoked by the script, the current product ID in the PRODUCTID session variable will be used. Once it's finished invoking the Details page scrapeable file, it will go on to the next row (or DataRecord) in the spreadsheet (or DataSet). Again, it will save the product ID in a session variable, then execute the Scrape details page script, which in turn invokes the Details page scrapeable file. Because we indicated that the script should be invoked After each pattern match, this will occur 10 times--once for each search result. If we had designated After pattern is applied, the script would only have been executed once: after it traversed the spreadsheet and reached the very end.
This is another area that people new to screen-scraper find confusing, so it's probably worth it to slow down a bit and ensure you understand what's going on.
Test Run
Now would be a good time to try out the whole scraping session again. Do what you did before by clearing out the log for the scraping session, then clicking the Run Scraping Session button. You'll see each details page getting requested one-by-one. Note especially each URL, which will have a different product ID at the end of each. If you'd prefer not to wait for the entire session to run you can click the Stop Scraping Session button.
As before, it would be a good idea to go through the log carefully to ensure that you understand what it's doing.
Scrape Search Results Script
At this point we still need to deal with the next page link. We already have an extractor pattern to grab out the page number of the next page. Let's create a script to scrape the search results page again for each next link.
Generate a new script and call it Scrape search results. Enter the following in the Script Text field:
session.scrapeFile( "Search results" );
Notice that we have only one line of code, short and simple, which will scrape the Search results scrapeable file when it is invoked.
Add Scrape Search Results Script Association
Return to the Next link extractor pattern and click the Add Script button to add a script association. Select the Scrape search results script.
This time there's something slightly different we'll need to do under the When to Run column. If you remember our extractor pattern matched twice (you can see this on the previous page). The problem is that we only want to follow the Next link once (that is, we don't want to scrape the second page twice). This is easily dealt with by selecting Once if pattern matches under the When to run column.
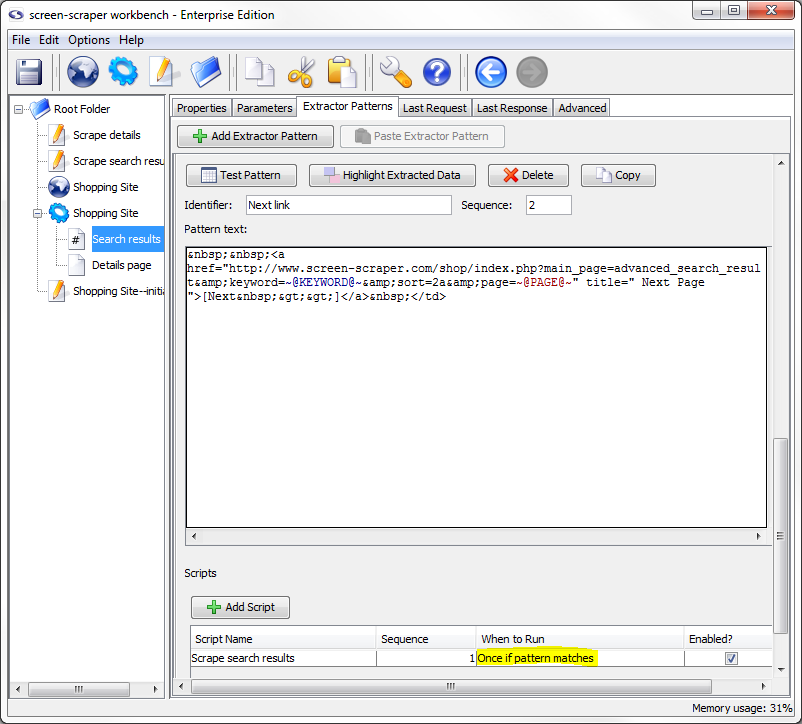
In other words, the script will only get invoked once and only if the extractor pattern has a match. Selecting Once if pattern matches under the When to run column guarantees that the script will get invoked once and only once regardless of the number of matches it finds. So, even though we have two matches for the Next link extractor pattern, the Scrape search results script will only be invoked once, which means that the Search results will only be scraped once.
Test Run
OK, run the scraping session once more. Clear the scraping session log, then click the Run Scraping Session button. If you let it run for a while you'll notice that it will request each details page for the products found on the first search results page, request the second search results page, then request each of the details pages for that page.
- Printer-friendly version
- Login or register to post comments