Script Repository
Welcome to the Script Repository. Here you will find a continually expanding resource for sharing scripts and ideas. The purpose of this resource is reduce the amount of programming experience you will need to successfully use screen-Scraper.
Throughout this Drupal Book you will find chapters with scripts on initializing, writing, iterating, and more! We hope that these will be a useful addition to your scraping experience.
Most of these scripts are written in Java, the development language of our choice. If you would like to suggest a script that you have created yourself, and wish for it to be publicly available, then send us an email from our contact us page.
Input
Overview
The basic idea of initializing is discussed in the second and third tutorials and serves one of two purposes:
- Prepare Objects: If you are saving the scraped information to a database, CSV, or XML file then you will likely want to initialize these objects before you start. Also, if you will be iterating over pages, you might need to start your iterator before the scrape begins.
- Debug Script: In this form the script is meant only to allow you to run a scrape with variables that will later be received from an external script but are required for it to run.
As you can guess, you might have both of these needs in a single script of in two different scripts. Regardless, here we present different methods for initializations scripts including such variables as where you get the values of your variables.
Input from CSV
This script is extremely useful because it's purpose is to enable you to read inputs in from a csv list. For Example, if you wanted to input all 50 state abbreviations as input parameters for a scrape then this script would cycle through them all. Furthermore, this script truly begins to show the power of an Initialize script as a looping mechanism.
This particular example uses a csv of streets in Bristol RI. Each street in Bristol is seperated by commas and only one street per line. The "while" loop at the bottom of the example retrieves streets one by one until the buffered reader runs out of lines. These streets are stored as a session variable named STREET and used as an input later on. Each time the buffered reader brings in a new street it blasts the last one out of the STREET session variable.
//you need to point the input file in the right direction. This is a relative path to an input folder in the location where you installed Screen-scraper.
session.setVariable("INPUT_FILE", "input/BRISTOL-STREETS.csv");
//this buffered reader gathers in the csv one line at a time. Your csv will need to be seperated into lines as well with one entity per line.
BufferedReader buffer = new BufferedReader(new FileReader(session.getVariable("INPUT_FILE")));
//because for this scrape my city was BRISTOL and my state was RI I set these as session variables to be used later as inputs.
session.setVariable("CITY", "BRISTOL");
session.setVariable("STATE", "RI");
//this is the loop that I was referring to earlier. As long as the line from the buffered reader is not null it sets the line as a session variable and //calls the "Search Results" scrapeable file.
while ( (line = buffer.readLine()) != null ){
session.setVariable("ZIP", line);
session.log("***Beginning zip code " + session.getVariable("ZIP"));
session.scrapeFile("Search Results");
}
buffer.close();
Reading in from a CSV is incredibly powerful; however, it is not the only way to use a loop. For information on how to use an array for inputs please see the "Moderate Initialize -- Input from Array".
The next script (below) deals with input CSV files that have more than one piece of information per row (more than one column).
////////////////////////////////////////////
session.setVariable("INPUT_FILE", "input/streets_towns.csv");
////////////////////////////////////////////
BufferedReader buffer = new BufferedReader(new FileReader(session.getVariable("INPUT_FILE")));
String line = "";
while (( line = buffer.readLine()) != null ){
String[] lineParts = line.split(",");
// Set the variables with the parts from the line
session.setVariable("CITY", lineParts[1]);
session.setVariable("STREET", lineParts[0]);
// Output to the log
session.log("Now scraping city: " + session.getVariable("CITY") + " and street: " + session.getVariable("STREET"));
// Scrape next scrapeable file
session.scrapeFile("MyScrape--2 Search Results");
}
buffer.close();
Read CSV
Sometimes a CSV file will use quotes to wrap data (in case that data contains a comma that does not signify a new field). Since it's a common thing to do, a script to read a CSV should anticipate and deal that that eventuality. The main workhorse of this script is the function. By passing a CSV line to it, it will parse the fields into an array.
int START_STATE = 0;
int FIRST_QUOTE = 1;
int SECOND_QUOTE = 2;
int IN_WORD = 3;
int IN_WORD_WITHOUT_QUOTES = 4;
int state = START_STATE;
String word = "";
ArrayList lines = new ArrayList();
char[] chars = line.toCharArray();
for (int i = 0; i < chars.length; i++){
char c = chars[i];
if (c == '"'){
if (state == START_STATE){
state = FIRST_QUOTE;
}
else if ((state == FIRST_QUOTE) || (state == IN_WORD)){
state = SECOND_QUOTE;
}
else if (state == SECOND_QUOTE){
word += ("" + c);
state = IN_WORD;
}
}
else if (c == ','){
if ((state == SECOND_QUOTE) || (state == IN_WORD_WITHOUT_QUOTES)){
state = START_STATE;
lines.add(word);
if (lines.size() == columnsToGet) break;
word = "";
}
else if (state == START_STATE){
state = START_STATE;
lines.add(word.replaceAll("\"\"", "\""));
}
else{
word += ("" + c);
state = IN_WORD;
}
}
else{
if (state == START_STATE) state = IN_WORD_WITHOUT_QUOTES;
else if (state != IN_WORD_WITHOUT_QUOTES){
state = IN_WORD;
word += ("" + c);
}
}
}
if (lines.size() < columnsToGet){
if ((state == SECOND_QUOTE) || (state == IN_WORD_WITHOUT_QUOTES))
lines.add(word.replaceAll("\"\"", "\""));
}
String[] linesArray = new String[lines.size()];
for (int i = 0; i < lines.size(); i++){
linesArray[i] = (String) lines.get(i);
}
return linesArray;
}
// File from which to read.
File inputFile = new File( "test_input.csv" );
FileReader in = new FileReader( inputFile );
BufferedReader buffRead = new BufferedReader( in );
// Read the file in line-by-line.
int index = 0;
while( ( searchTerm = buffRead.readLine() )!=null){
// Don't read header row
if (index>0){
// Parse the line into an array
line = parseCSVLine(searchTerm, index, 5);
// Get the values
name = line[0];
date = line[1];
address = line[2];
city = line[3];
state = line[4];
zip = line[5];
// Set the needed values as session vaiables
session.setVariable("NAME", name);
session.setVariable("ZIP", zip);
// Scrape for those values
session.scrapeFile("Serach results");
}
index++;
}
// Close up the file.
in.close();
buffRead.close();
Alternatively you can read the csv via the opencsv package that is included with screen-scraper. This may be more robust for different formats of csv
//initialize the reader
File f = new File("input/AK.csv");
CSVReader reader = new CSVReader(new FileReader(f));
//read the file saving it into a List of Maps
String[] headers = reader.readNext();
List lines = new ArrayList();
String[] line;
while((line = reader.readNext())!=null)
{
Map m = new HashMap();
for(int i=0;i<headers.length;i++)
{
m.put(headers[i],line[i]);
}
lines.add(m);
}
reader.close();
//print out what we read
for(int i=0;i<lines.size();i++)
{
session.log(String.valueOf(lines.get(i)));
}
Input from array
The following script is really useful when you need to loop through a short series of input parameters. Using an array will allow you to rapidly develop a group of inputs that you would like to use; however, you will need to know every input parameter. For example, if you wanted to use the following state abbreviations as inputs [UT, NY, AZ, MO] then building an array would be really quick, but if you needed all 50 states it would probably be easier to access those from a csv (need to know how to use a csv input? check out my other post titled "Moderate Initialize -- Input from CSV").
String[] states = {"DE", "FL", "GA", "MD", "NH", "NC", "PA", "RI", "SC", "TN", "VT", "VA", "MS"};
int i = 0;
while ( i<states.length )
{
if (!session.shouldStopScraping())
{
session.setVariable("STATE", states[i]);
session.log("***Beginning STATE: " + session.getVariable("STATE"));
session.scrapeFile("Search Results");
i++;
}
}
Input from multiple files
Many sites requiring the user to input a zip code when performing a search. For example, when searching for car listings, a site will ask for the zip code where you would like to find a car (and perhaps distance from the entered zip code that would be acceptable). The follow script is designed to iterate through a set of input files, which each contain a list of zip codes for that state. The input files in this case are located within a folder named "input" in the screen-scraper directory. The files are named in the format "zips_CA", for example, which would contain California's zip codes.
String[] states = {"AL", "AK", "AZ", "AR", "CA", "CO", "CT", "DE", "DC", "FL", "GA", "HI", "ID", "IL", "IN", "IA", "KS", "KY", "LA", "ME", "MD", "MA", "MI", "MN", "MS", "MO", "MT", "NE", "NV", "NH", "NJ", "NM", "NY", "NC", "ND", "OH", "OK", "OR", "PA", "PR", "RI", "SC", "SD", "TN", "TX", "UT", "VT", "VA", "WA", "WV", "WI", "WY"};
i = 0;
// Iterate through each state abbreviation in the array above
while (i < states.length){
////////////////////////////////////////////
// The file changes depending on what state we are scraping
session.setVariable("INPUT_FILE", "input/zips_"+ states[i] + ".csv");
////////////////////////////////////////////
BufferedReader buffer = new BufferedReader(new FileReader(session.getVariable("INPUT_FILE")));
String line = "";
while ((line = buffer.readLine()) != null){
// The input file in this case will have one zip code per line
session.setVariable("ZIPCODE", line);
session.log("***Beginning zip code " + session.getVariable("ZIPCODE"));
// Scrape the "Search Results" with the new zip code retrieved from the
// current state's file
session.scrapeFile("Search Results");
}
i++;
}
| Attachment | Size |
|---|---|
| zips_AL.csv | 5.73 KB |
| zips_AR.csv | 4.16 KB |
| zips_AZ.csv | 3.03 KB |
| zips_CA.csv | 20.7 KB |
| zips_CO.csv | 4.53 KB |
Simply Set Variables
When a Scraping Session is started it can be a good idea to feed certain pieces of information to the session before it begins resolving URLs. This simple version of the Initialize script is to demonstrate how you might start on a certain page. While basic, understanding when a script like this would be used is pivotal in making screen scraper work for you.
session.scrapeFile( "Your First Page Goes Here!" );
The above code is useful where "PAGE" is an input parameter in the first page you would like to scrape.
Occasionally a site will be structured so that instead of page numbers the site displays records 1-10 or 20-29. If this is the case your Initialize script could look something like this:
session.setVariable( "DISPLAY_RECORD_MAX", 10 );
session.scrapeFile( "Your First Page Goes Here!" );
Once again "DISPLAY_RECORD_MIN" and "DISPLAY_RECORD_MAX" are input parameters on the first page you would like to scrape.
If you feel you understand this one, I'd encourage you to check out the other Initialize scripts in this code repository.
U.S. Zip codes (CSV Files)
The following files contains zipcodes for the that state. The file "zips_US.CSV" contains all US zip codes within one file. If you wish to download all of the CSVs at once you may choose to download the file "zips_all_states.zip".
Note: If you've forgotten the state abbreviations please visit http://www.usps.com/ncsc/lookups/usps_abbreviations.html
Last updated 5/8/2008
| Attachment | Size |
|---|---|
| zips_AL.csv | 5.73 KB |
| zips_AR.csv | 4.16 KB |
| zips_AZ.csv | 3.03 KB |
| zips_CA.csv | 20.7 KB |
| zips_CO.csv | 4.53 KB |
| zips_CT.csv | 2.58 KB |
| zips_DE.csv | 686 bytes |
| zips_FL.csv | 10.1 KB |
| zips_GA.csv | 5.92 KB |
| zips_IA.csv | 6.25 KB |
| zips_ID.csv | 1.94 KB |
| zips_IL.csv | 9.31 KB |
| zips_IN.csv | 5.79 KB |
| zips_KY.csv | 6.87 KB |
| zips_LA.csv | 4.21 KB |
| zips_MA.csv | 4.17 KB |
| zips_MD.csv | 4.23 KB |
| zips_ME.csv | 2.98 KB |
| zips_MI.csv | 6.84 KB |
| zips_MN.csv | 6.05 KB |
| zips_MO.csv | 6.98 KB |
| zips_NC.csv | 7.43 KB |
| zips_ND.csv | 2.41 KB |
| zips_NE.csv | 3.65 KB |
| zips_NH.csv | 1.65 KB |
| zips_NJ.csv | 4.33 KB |
| zips_NM.csv | 2.5 KB |
| zips_NV.csv | 1.47 KB |
| zips_NY.csv | 13.04 KB |
| zips_OH.csv | 8.54 KB |
| zips_OK.csv | 4.55 KB |
| zips_OR.csv | 2.82 KB |
| zips_PA.csv | 15.06 KB |
| zips_RI.csv | 546 bytes |
| zips_SC.csv | 3.68 KB |
| zips_SD.csv | 2.36 KB |
| zips_TN.csv | 5.43 KB |
| zips_TX.csv | 18.09 KB |
| zips_UT.csv | 2 KB |
| zips_VA.csv | 8.51 KB |
| zips_VT.csv | 1.8 KB |
| zips_WA.csv | 4.21 KB |
| zips_WI.csv | 5.31 KB |
| zips_WV.csv | 5.89 KB |
| zips_WY.csv | 1.14 KB |
| zips_all_states.zip | 178.54 KB |
| zips_US.csv | 295.08 KB |
Forms
The form class can be a life saver when it comes to dealing with sites that use forms for their inputs and have a lot of dynamic parameters
There are really only two cases in which using the form class is preferrable to doing the paramenters any other way. Those cases are:
- The page is using a bunch of dynamic parameters (number of keys and/or names of keys changing)
- This goes with the other, but if you get to a page that has data filled in already you just want to submit as-is, but it won't always be the same
In general though, it'll be easier for debugging if you can stick with the regular parameter tab
Form Creation
// The form text being built should include the form open and close tag.
// Any inputs are used, not just what is inside the form tags, so
// limit the input text to the form area. If there is only one
// form on the page you can use scrapeableFile.getContentBodyOnly()
// as this doesn't care what additional text is included.
Form form = scrapeableFile.buildForm(dataRecord.get("TEXT"));
// Be sure to save the form in a session variable so it can be used
// by the scrapeable file which will use the form data
session.setVariable("_FORM", form);
// The form object is now ready to be used to submit what is currently
// on the page, or can be manipulated with input values being set
// Set a value on the form. If the form didn't contain that input key,
// one will be added for it
form.setValue("zip", "12345");
// Set a value on the form, but validate it can be set to that. This isn't
// fool proof, but does some checking. For instance, if the input was
// a select type, it will throw an exception if there wasn't an option
// with the given value. It also handles some other error checking based
// on the input type, but any Javascript checks won't be checked
form.setValueChecked("selector", "op1");
// Remove the specified input from the form. This is useful if there are
// multiple submit buttons, for instance. In that case the one that
// is clicked on is the value sent to the server..
form.removeInput("Update");
Form Use
// To use the form data, it needs to be set in a script run
// "Before file is scraped"
// Get the form from the session (or where ever it is stored)
Form form = session.getVariable("_FORM");
// Call this method to set the values. This includes the URL
// if a URL was found in the form tag when building the form
form.setScrapeableFileParameters(scrapeableFile);
Iteration
Overview
One of the most common things to need is the ability to iterate over the results of a search. This usually requires the ability to iterate over the same page with changes to the parameters that are passed. There are examples of this in the second and third tutorials.
There are different methods to use and one thing to keep in mind: memory. This is especially important on larger scrapes and for basic users where the number of scripts on the stack needs to be watched. Below are some examples of Next Page scripts. Which you choose to use will depend on what is available and what your needs are.
Memory Conscious Next Page
If you're scraping a site with lots of "next page" links, you are well advised to use the following script, instead of the other two listed here.
Conceptually, the problem with calling a script at the end of a scrapeableFile, which calls the same scrapeableFile over and over again, is that you're stacking the scrapeableFiles on top of one another. They'll never leave memory until the last page has completed, at which point the stack quickly goes away. This style of scraping is called "recursive".
If you can't predict how many pages there will be, then this idea should scare you :) Instead, you should use an "iterative" approach. Instead of chaining the scrapeableFiles on the end of one another, you call one, let it finish and come back to the script that called it, and then the script calls another. A while/for loop is very fit for this.
Here's a quick illustration of a comparison, so that you can properly visualize the difference. Script code to follow.
search results for category "A"
|- next results
|- next results
|- next results
|- next results
search results for category "B"
|- next results
|- next results
|- next results
|- next results
|- next results
|- next results
// Now here's the for-loop "iterative" approach, via a single control script:
search results for category "A"
next results
next results
next results
next results
search results for category "B"
next results
next results
next results
next results
next results
next results
Much more effective.
So here's how to do it. When you get to the point where you need to start iterating search results, call a script which will be a little controller for the iteration of pages. This will handle page numbers and offset values (in the event that page iteration isn't using page numbers).
First, your search results page should match some extractor pattern which hints that there is a next page. This helps remove what the page number actually is, and reduces next pages to a simple boolean true or false. The pattern should match some text that signifies a next page is present. In the example code below, I've named the variable "HAS_NEXT_PAGE". Be sure to save it to a session variable. If there is no next page, then this variable should not be set at all. That will be the flag for the script to stop trying to iterate pages.
int initialOffset = 0;
// ... and this number is the amount that the offset increases by each
// time you push the "next page" link on the search results.
int offsetStep = 20;
String fileToScrape = "Search Results ScrapeableFile Name";
/* Generally no need to edit below here */
hasNextPage = "true"; // dummy value to allow the first page to be scraped
for (int currentPage = 1; hasNextPage != null; currentPage++)
{
// Clear this out, so the next page can find its own value for this variable.
session.setVariable("HAS_NEXT_PAGE", null);
session.setVariable("PAGE", currentPage);
session.setVariable("OFFSET", (currentPage - 1) * offsetStep + initialOffset);
session.scrapeFile(fileToScrape);
hasNextPage = session.getVariable("HAS_NEXT_PAGE");
}
The script provides to you a "PAGE" session variable, and an "OFFSET" session variable. Feel free to use either one, whichever your situation calls for.
OFFSET will (given the default values in the script), be 0, 20, 40, 60, etc, etc.
PAGE will be 1, 2, 3, 4, 5, etc, etc.
Next Page Link
The following script is called upon completion of scraping the first page of a site's details. This script is useful when matching the current page number in the HTML is preferable or simpler than matching the next page number. Depending on how a site is coded, the number of the next page may not even appear on the current page. In this case, we would match for the word "Next", to simply determine if a next page exists or not. The regular expression used for the word next would be used as follows:
The regular expression for the lone token ~@NEXT@~ would be the text that suggests that a next page exists, such as Next Page or maybe a simple >> link.
The only change you should have to make to the code below is to set any variable names properly (if different than in your own project), and to set the correct scrapeableFile name near the bottom.
// Check to see if we found the word or phrase that flags a "Next" page
if (session.getVariable("NEXT") != null)
{
// Retrieve the page number of the page just scraped
currentPage = session.getVariable("PAGE");
if (currentPage == null)
currentPage = 1;
else
currentPage = Integer.parseInt(currentPage).toString();
// write out the page number of the page just scraped
session.log("Last page was: " + currentPage);
// Increment the page number
currentPage++;
// write out the page number of the next page to be scraped
session.log("Next page is: " + currentPage);
// Set the "PAGE" variable with the incremented page number
session.setVariable("PAGE", currentPage);
// Clear the "NEXT" variable so that the next page is allowed to find it's own value for "NEXT"
session.setVariable("NEXT", null);
// Scrape the next page
session.scrapeFile("Scraping Session Name--Next Page");
}
Simple Next Page
One of our fellow contributors of this site posted a Next Page script which can be very useful, but may be more code than what you might need. Because every site is constructed differently, iterating through pages can be one of the most difficult parts for a new screen-scraper to master. Indeed, the design of how to get from page to page typically takes some creativity and precision.
One initial word of warning about going from page to page. Occasionally a site will be designed so you can get to the next page at the top and the bottom of the current page. Everybody has seen these before. For example, you're looking through a site which sells DVDs and at the top and the bottom of the list there is a group of numbers that shows what page you are currently viewing, the previous page, the next page, and sometimes the last page. The problem occurs when your pattern matches for the next page before you get to the data you want extracted. If that is the case, your session begins to flip through pages at a very fast rate without retrieving any information at all! Do yourself a favor and match for the one at the bottom of the page.
After you have a successful match, the following script can be applied "Once if pattern matches".
We realize that it is only one line of code, but in many cases that is all that it needs to be.
Iterate over DataSets & DataRecords
myDataRecord = new DataRecord();
if (session.getVariable("A") != null && session.getVariable("A") != "")
{
myDataRecord.put("A",session.getVariable("A"));
}
if (session.getVariable("B") != null && session.getVariable("B") != "")
{
myDataRecord.put("B",session.getVariable("B"));
}
if (session.getVariable("C") != null && session.getVariable("C") != "")
{
myDataRecord.put("C",session.getVariable("C"));
}
dataSet.addDataRecord( myDataRecord );
session.log("how many fields in myDataRecord? " + myDataRecord.size());
int totalValues = 0;
for (int i=0; i<dataSet.getNumDataRecords(); i++)
{
dr = dataSet.getDataRecord(i);
enumeration = dr.keys();
while (enumeration.hasMoreElements())
{
key = enumeration.nextElement();
value = dr.get(key);
session.log("key:value **" + key + ":" + value + "**");
totalValues += Integer.parseInt(value).intValue();
}
}
session.log("Sum of all values for this dataRecord: " + totalValues);
session.log("Average of the sum of all values: " + (totalValues / dr.size()));
// Remove all DataRecord objects from the dataSet object.
dataSet.clearDataRecords();
Manual Data Extraction
A sub-extractor pattern can only match one element but manual data extraction allows you to give the same additional context information as using a sub-extractor pattern but allows you the ability to extract multiple data records.
This example makes use of the extractData() method.
The code and examples below demonstrate how to first isolate and extract a portion of a page's total HTML, so that a second extractor pattern may then be applied to just the extracted portion. Doing so can limit the results to only those found on a specific part of the page. This can be useful when you have 100 apples that all look the same but you really only want five of them.
The following screen shots show an example of when the script above might be used. In this example, we are only interested in the active (shown with green dots) COMPANY APPOINTMENTS, and not the LICENSE AUTHORITIES (sample HTML available at the end).
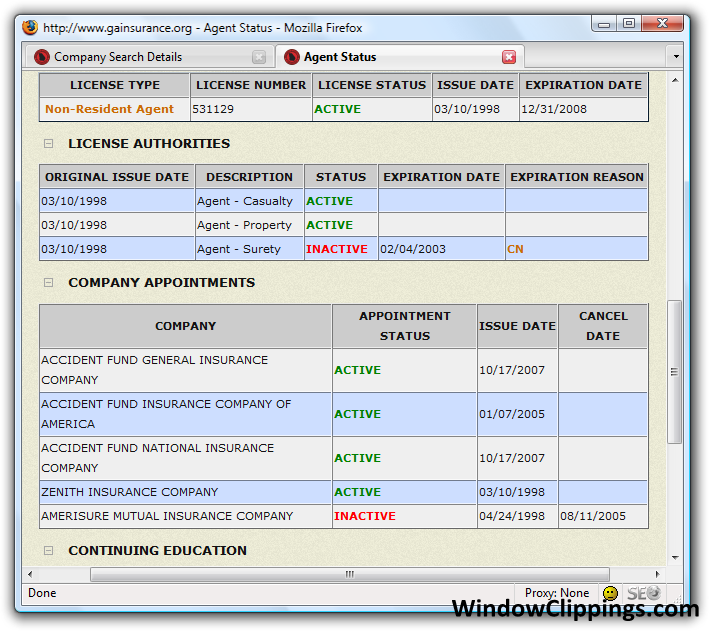
When applied to the all of the HTML of the current scrapeable file, the following extractor pattern will retrieve ALL of the html that makes up the COMPANY APPOINTMENTS table above. But, remember, we only want the active appointments.
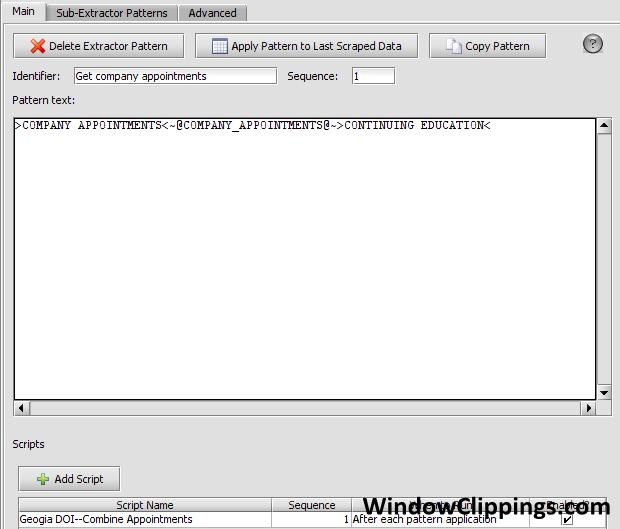
//Create a local variable called appointments to store the dataset that is generated when you
//MANUALLY apply the "Appointments" extractor pattern to the already extracted data that
//resulted from the application of the COMPANY_APPOINTMENTS extractor pattern.
DataSet appointments = scrapeableFile.extractData(dataRecord.get("COMPANY_APPOINTMENTS"), "Appointments");
// ^^token name^^ ^^extractor id^^
// Start the local variable allAppointments where we will one-by-one append the values of each
//matching appointment. Separate them with the pipe character "|".
allAppointments = "";
// Take the appointments dataSet generated from above and loop through
//each of the successful matches that are stored as records.
for (i=0; i < appointments.getNumDataRecords(); i++)
{
// Grab the current dataRecord from the looping dataSet
appointmentRecord = appointments.getDataRecord(i);
// Grab the results of the applied ~@APPOINTMENT@~ token
// referencing it by name.
// Note: it's possible to reference more than one token here
appointment = appointmentRecord.get("APPOINTMENT");
// Append the current appoinment to the growing list of matches
allAppointments += appointment + " | ";
}
// When the loop is done, store the results in a session variable
session.setVariable("APPOINTMENTS", allAppointments);
// Write them out to log to see if they look right
session.log("The appointments are: " + allAppointments);
<div id="Level3" style="Display: Block; position: relative; text-align: center">
<table class="verysmalltext" width="90%" border="1" cellpadding="1" cellspacing="0" bordercolor="#BBBBBB">
<tr bgcolor="#CCCCCC">
<th class="bold">COMPANY</th>
<th class="bold">APPOINTMENT STATUS</th>
<th class="bold">ISSUE DATE</th>
<th class="bold">CANCEL DATE</th>
</tr>
<tr bgcolor="#CDDEFF">
<td class="small">21ST CENTURY INSURANCE COMPANY </td>
<td class="small" style="color: GREEN"><b>ACTIVE</b> </td>
<td class="small">05/05/2006 </td>
<td class="small"> </td>
</tr>
<tr bgcolor="#EFEFEF">
<td class="small">AIG CENTENNIAL INSURANCE COMPANY </td>
<td class="small" style="color: GREEN"><b>ACTIVE</b> </td>
<td class="small">01/30/2008 </td>
<td class="small"> </td>
</tr>
<tr bgcolor="#CDDEFF">
<td class="small">BALBOA INSURANCE COMPANY </td>
<td class="small" style="color: RED"><b>INACTIVE</b> </td>
<td class="small">05/15/2006 </td>
<td class="small">04/23/2008 </td>
</tr>
</table>
<blockquote><img name="Image4" class="mouseover" onmouseover="this.style.cursor=" src="/MEDIA/images/gifs/squareminus.gif" onclick="visAction('Level4')" /> <b>
Use the extractor pattern below to match against the HTML above. It will return two results: 21ST CENTURY INSURANCE COMPANY, and AIG CENTENNIAL INSURANCE COMPANY, since those are the only two active company appointments. Note that the "Appointment" Extractor Pattern includes the word "GREEN", so that the "RED"(Inactive) company appointments are excluded.
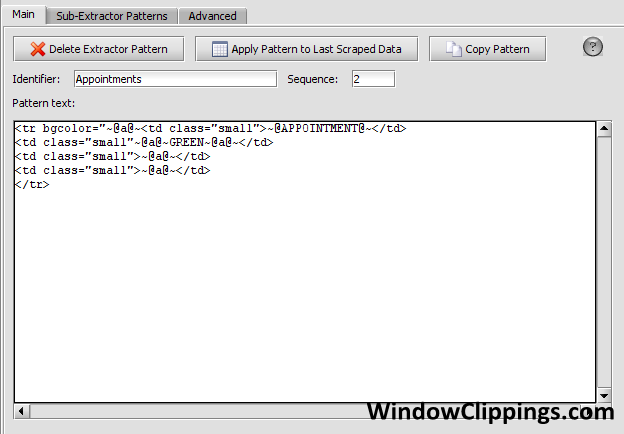
Be sure to check the box that says "This extractor pattern will be invoked manually from a script". This will ensure that the extractor pattern will not run in the sequence with the other extractor patterns.
<div id="Level2" style="Display: Block; position: relative; text-align: center">
<table class="verysmalltext" width="90%" border="1" cellpadding="1" cellspacing="0" bordercolor="#BBBBBB">
<tr bgcolor="#CCCCCC">
<th class="bold">ORIGINAL ISSUE DATE</th>
<th class="bold">DESCRIPTION</th>
<th class="bold">STATUS</th>
<th class="bold">EXPIRATION DATE</th>
<th class="bold">EXPIRATION REASON</th>
</tr>
<tr bgcolor="#CDDEFF">
<td>01/31/2006 </td>
<td>Agent - Property </td>
<td style="color: GREEN"><b>ACTIVE</b> </td>
<td> </td>
<td style='cursor:hand' onmouseover="this.style.cursor='pointer'" title='no information'><b style="color: #CA6C04"> </b></td>
</tr>
<tr bgcolor="#EFEFEF">
<td>01/31/2006 </td>
<td>Agent - Casualty </td>
<td style="color: GREEN"><b>ACTIVE</b> </td>
<td> </td>
<td style='cursor:hand' onmouseover="this.style.cursor='pointer'" title='no information'><b style="color: #CA6C04"> </b></td>
</tr>
</table>
</div>
<blockquote><img name="Image3" class="mouseover" onmouseover="this.style.cursor=" src="/MEDIA/images/gifs/squareminus.gif" onclick="visAction('Level3')" /> <b>COMPANY APPOINTMENTS</b></blockquote>
<div id="Level3" style="Display: Block; position: relative; text-align: center">
<table class="verysmalltext" width="90%" border="1" cellpadding="1" cellspacing="0" bordercolor="#BBBBBB">
<tr bgcolor="#CCCCCC">
<th class="bold">COMPANY</th>
<th class="bold">APPOINTMENT STATUS</th>
<th class="bold">ISSUE DATE</th>
<th class="bold">CANCEL DATE</th>
</tr>
<tr bgcolor="#CDDEFF">
<td class="small">21ST CENTURY INSURANCE COMPANY </td>
<td class="small" style="color: GREEN"><b>ACTIVE</b> </td>
<td class="small">05/05/2006 </td>
<td class="small"> </td>
</tr>
<tr bgcolor="#EFEFEF">
<td class="small">AIG CENTENNIAL INSURANCE COMPANY </td>
<td class="small" style="color: GREEN"><b>ACTIVE</b> </td>
<td class="small">01/30/2008 </td>
<td class="small"> </td>
</tr>
<tr bgcolor="#CDDEFF">
<td class="small">BALBOA INSURANCE COMPANY </td>
<td class="small" style="color: RED"><b>INACTIVE</b> </td>
<td class="small">05/15/2006 </td>
<td class="small">04/23/2008 </td>
</tr>
</table>
</div>
<blockquote><img name="Image4" class="mouseover" onmouseover="this.style.cursor=" src="/MEDIA/images/gifs/squareminus.gif" onclick="visAction('Level4')" /> <b>CONTINUING EDUCATION
Scrape Only Recent Information
This script is designed to check how recent a post or advertisement is. If you were gathering time sensitive information and only wanted to reach back a few days then this script would be handy. After evaluating the date there will be a section for calling other scripts from inside this script.
import java.util.Date;
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.lang.*;
import java.util.*;
import java.io.*;
// Function to parse the passed string into a date
makeDate(date)
{
//This is the format for your date. It is in the April 20, 1999 format
formatter = new SimpleDateFormat("MMM d, yyyy");
//some other options instead of blank could be null, N/A, etc. Really it just depends on how the site is structured.
if (date.equals("BLANK")){
session.log(" ---NO ATTEMPT TO PARSE BLANK DATE");
}
//if it is not blank go ahead and parse the data and apply the Format above. This will also print the date to the log.
else{
date = (Date)formatter.parse(date);
session.log(" +++Parsed date " + date);
}
return date;
}
// Function to get current date
oldestDate(){
// Set number of days to minus from current date.
minusDays = -5;
// Get the current date or instance, then you are going to add a negative amount of days. If that seems strange
// Just trust us. This is not a double negative thing.
Calendar rightNow = Calendar.getInstance();
rightNow.add( Calendar.DATE, minusDays );
// Substitute the Date variable endDate for rightNow becuase it makes more sense to
// Return endDate than a variable named rightNow which is 5 days in the past.
Date endDate = rightNow.getTime();
session.log("The end date is: " + endDate);
return endDate;
}
// Parse posted date. you are getting this posted date from a dataRecord.
// if you were getting it from a session variable it would say session.getVariable("POSTED_DATE")
posted = makeDate(dataRecord.get("POSTED_DATE"));
// Parse the current Date and return it in a format that you can compare to the advertisement or post date.
desired = oldestDate();
// Compare the two.<br />
if (posted.after(desired) || posted.equals(desired))
{
session.log ("AD IS FRESH. SCRAPING DETAILS.");
// If you are keeping track of URLs this will get it from the scrapeable file.
session.setVariable ("SOURCE_URL", scrapeableFile.getCurrentURL() );
// This is the place in the code where you would execute additional scripts.
session.executeScript("Your script name here");
session.executeScript("Your second script name here");
}
else{
session.log("Posted is too old");
}
Hopefully it is evident that the above code is useful in comparing todays date against a previous one. Depending on your needs you might consider developing a script which will move your scraping session on after it reaches a certain date in a listing. For example if you were scraping an auction website for many terms you might want to move on to the next term after you have reached a specified date for the listings. What are some other ways this script could be useful?
Output
Overview
There are many ways to output scraped data from screen-scraper. Below are sample scripts of some common ways.
Prepare For Output--Fix Phone
The following script contains a method that you may instead wish to call from within your "Write to CSV" script. The purpose of the script is to put phone numbers into a standard format (123-456-7890 x 1234) prior to output. Note: Be careful when using this script to work with non-U.S. phone numbers, since other countries may have more or fewer digits.
if (phone!=null && phone!=void){
session.log("+++Dealing with phone formated: " + phone);
// Replace non-digits with nothing
// Note: "\\D" is a regular expression that means "not a digit"
phone = phone.replaceAll("\\D", "");
// If there is a leading 1, remove it
if (phone.startsWith("1")){
session.log("+++Starts with a one, so removing.");
phone = phone.substring(1,phone.length());
}
// Reformat the phone to the format: "123-456-7890"
if (phone.length()>=10){
area = phone.substring(0,3);
prefix = phone.substring(3,6);
number = phone.substring(6,10);
newPhone = "(" + area + ") " + prefix + "-" + number;
}
else{
session.log("---Error: phone number hasn't enough digits");
}
// Deal with phone extensions
if (phone.length()>10){
newPhone += " x";
newPhone += phone.substring(10,phone.length());
}
}
return "\"" + ((newPhone==null || newPhone==void)? "" : newPhone ) + "\"";
}
Prepare For Output--Parse Full Name (including suffixes)
The following script proves useful in most cases when there is a need to separate a full name into first name, middle name, surname, and suffixes (if applicable). The suffixes include JR, SR, I, II, III, 3rd, IV, V, VI, VII. The script is also set up to work with names in the "LASTNAME, FIRSTNAME SUFFIX" format.
// a suffix.
boolean isSuffix( String value )
{
session.log( "Determining whether or not this is a suffix: " + value );
value = value.toUpperCase();
returnVal = (
value.indexOf( "JR" )!=-1
||
value.indexOf( "SR" )!=-1
||
value.equals( "I" )
||
value.equals( "II" )
||
value.equals( "III" )
||
value.equals( "3RD" )
||
value.equals( "IV" )
||
value.equals( "V" )
||
value.equals( "VI" )
||
value.equals( "VII" )
);
session.log( "Suffix test returning: " + returnVal );
return returnVal;
}
fixName( String name )
{
name = name.replaceAll(",", "").trim();
return name;
}
name = dataRecord.get("NAME");
name = name.replaceAll(" ", " ");
name = name.replaceAll("\\.", "");
name = name.replaceAll(";", " ");
name = name.replaceAll("[ ]{2,}", " ").trim();
lastName = "";
firstName = "";
middleName = "";
suffix = "";
session.log( "@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@" );
session.log( "NAME: " + name );
session.log( "@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@" );
// Split on the space.
nameParts = name.split( " " );
// Send the parts to the log.
for( int i = 0; i < nameParts.length; i++ )
{
session.log( "Name part #" + i + ": " + nameParts[i] );
}
// If the first part has a comma we assume it's the last name.
if( nameParts.length > 1 && nameParts[0].indexOf( "," )!=-1 )
{
session.log( "The first name part has a comma." );
// If we have two elements we assume the order is
// last name, first name.
if( nameParts.length==2 )
{
lastName = fixName(nameParts[0]);
firstName = fixName(nameParts[1]);
}
// If we have three elements we assume the order is
// either last name, first name, middle name or
// last name, first name suffix.
else if( nameParts.length==3 )
{
if( !isSuffix( nameParts[2] ) )
{
lastName = fixName(nameParts[0]);
firstName = fixName(nameParts[1]);
middleName = fixName(nameParts[2]);
}
else
{
lastName = fixName(nameParts[0]);
firstName = fixName(nameParts[1]);
suffix = fixName(nameParts[2]);
}
}
else if( nameParts.length==4 )
{
// It will either be last name, first name middle name middle name or
// last name, first name middle name suffix.
if( !isSuffix( nameParts[3] ) )
{
lastName = fixName(nameParts[0]);
firstName = fixName(nameParts[1]);
middleName = fixName(nameParts[2]) + " " + fixName(nameParts[3]);
}
else
{
lastName = fixName(nameParts[0]);
firstName = fixName(nameParts[1]);
middleName = fixName(nameParts[2]);
suffix = fixName(nameParts[3]);
}
}
}
// If we have four parts and no comma it's either First Name Middle Name Middle Name Last Name or
// First Name Middle Name Last Name Suffix.
else if( nameParts.length==4 )
{
session.log( "The name has four elements." );
if( !isSuffix( nameParts[3] ) )
{
firstName = fixName(nameParts[0]);
middleName = fixName(nameParts[1]) + " " + fixName(nameParts[2]);
lastName = fixName(nameParts[3]);
}
else
{
firstName = fixName(nameParts[0]);
middleName = fixName(nameParts[1]);
lastName = fixName(nameParts[2]);
suffix = fixName(nameParts[3]);
}
}
// If we have three parts and no comma it's either First Name Middle Name Last Name or
// First Name Last Name Suffix.
else if( nameParts.length==3 )
{
session.log( "The name has three elements." );
if( !isSuffix( nameParts[2] ) )
{
firstName = fixName(nameParts[0]);
middleName = fixName(nameParts[1]);
lastName = fixName(nameParts[2]);
}
else
{
firstName = fixName(nameParts[0]);
lastName = fixName(nameParts[1]);
suffix = fixName(nameParts[2]);
}
}
// If the first part doesn't have a comma we assume the first
// name is given first.
else
{
// If we have only two parts we assume first name then last name.
if( nameParts.length==2 )
{
firstName = fixName(nameParts[0]);
middleName = "";
lastName = fixName(nameParts[1]);
}
}
session.log( "####################################################" );
session.log( "FIRST NAME: " + firstName );
session.log( "MIDDLE NAME: " + middleName );
session.log( "LAST NAME: " + lastName );
session.log( "SUFFIX: " + suffix );
session.log( "####################################################" );
dataRecord.put( "FNAME", firstName );
dataRecord.put( "MNAME", middleName );
dataRecord.put( "LNAME", lastName );
dataRecord.put( "SUFFIX", suffix );
Prepare For Output--Parse Zipcode
The following code is used to split zip codes from a pattern match. The code below takes a zip code and assigns the first five digits to the variable "ZIP". If the zip code is in the longer format (12345-6789), as opposed to the shorter format (12345), then the second part of the zip code, which comes after the "-" character, is assigned to the "ZIP4" variable (so named for the 4 digits following the "-" character). This script would be useful in cases where zip codes must be standardized.
// Local reference to variables
String zip = dataRecord.get("ZIP");
if(zip != null){
// Split the zip code on the "-" character (for zip codes in the 12345-6789 format)
String[] zipParts = zip.split("-");
// Put parts in dataRecord
dataRecord.put("ZIP", zipParts[0]);
// If we were able to split the zip into two pieces (for zip codes in the 12345-6789 format),
// then we store the last four digits in the variable "ZIP4"
if (zipParts.length == 2){
dataRecord.put("ZIP4", zipParts[1]);
}
}
}
catch(Exception e){
session.log("Error running Fix Zip Codes and Nulls");
}
Prepare For Output--Strip non-numbers
This is a simple script used from removing all non-numerical characters from numbers. This is particularly useful when attempting to normalize data before insertion into a database.
i = 0;
// Iterate through each variable in the array above
while (i < variables.length){
//Get the variables to be fixed
value = session.getVariable(variables[i]);
//Log the UNFIXED values
session.log("UNFIXED: " + variables[i] + " = " + value);
if(value != null){
//Remove non-numerical elements from number
value = value.replaceAll("\\D","");
// Set variables with new values
dataRecord.put(variables[i], value);
session.setVariable(variables[i], value);
//Log the FIXED values
session.log("FIXED " + variables[i] + " = " + session.getVariable(variables[i]));
}
i++;
}
Write to CSV
Probably the easiest way to write to a comma-seperated value (CSV) document is to use screen-scrapers included CsvWriter. If for some reason you can't/don't wish to use the CsvWriter the following code will also accomplish the task. CSV files are very useful for viewing in spreadsheets or inserting values into a database.
Also, you'll notice that the session variables are cleared out at the end of the script. This would be done when you don't want a session variable to persist into the next dataRecord. For more about scope and dataRecords please go here.
import java.text.DateFormat;
import java.text.SimpleDateFormat;
// Date/time string to add to filename or column
String getDateTime()
{
DateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd_hhmmss");
Date date = new Date();
return dateFormat.format(date);
}
// Fix format issues, and return wrapped in quotes
String fixString(String value)
{
if (value != null)
{
value = sutil.convertHTMLEntities(value);
value = value.replaceAll("\"", "\'");
value = value.replaceAll("\\s{2,}", " ");
value = value.trim();
}
return "\"" + (value==null ? "" : value) + "\"";
}
String fixPhone(String phone)
{
if (phone!=null)
{
phone = phone.replaceAll("\\D", "");
// If there is a leading 1, remove it
if (phone.startsWith("1"))
{
session.log("+++Starts with a one, so removing.");
phone = phone.substring(1,phone.length());
}
if (phone.length()>=10)
{
area = phone.substring(0,3);
prefix = phone.substring(3,6);
number = phone.substring(6,10);
newPhone = "(" + area + ") " + prefix + "-" + number;
}
// Deal with extensions
if (phone.length()>10)
{
newPhone += " x";
newPhone += phone.substring(10,phone.length());
}
}
return ((newPhone==null || newPhone==void) ? "" : newPhone) ;
}
// Set name of file to write to
// outputFile = "output/" + session.getName() + "_" + getDateTime() + ".csv";
outputFile = "output/" + session.getName() + ".csv";
// Set columns to write
// Will look for tokens of same name using usual naming convention
String[] names = {
"Dealer",
"Address1",
"Address2",
"City",
"State",
"Post code",
"Country",
"Phone",
"Fax"
};
try
{
File file = new File(outputFile);
fileExists = file.exists();
// Open up the file to be appended to
out = new FileWriter(outputFile, true);
session.log("Writing data to a file");
if (!fileExists)
{
// Write headers
for (i=0; i<names.length; i++)
{
out.write(names[i]);
if (i<names.length-1)
out.write(",");
}
out.write("\n");
}
// Write columns
for (i=0; i<names.length; i++)
{
var = names[i];
var = var.toUpperCase();
var = var.replaceAll("\\s", "_");
out.write(fixString(dataRecord.get(var)));
if (i<names.length-1)
out.write(",");
}
out.write( "\n" );
// Close up the file
out.close();
// Add to controller
session.addToNumRecordsScraped(1);
}
catch( Exception e )
{
session.log( "An error occurred while writing the data to a file: " + e.getMessage() );
}
Writing extracted data to XML
Overview
Oftentimes once you've extracted data from a page you'll want to write it out to an XML file. screen-scraper contains a special XmlWriter class that makes this a snap.
This script uses objects and methods that are only available in the enterprise edition of screen-scraper.
To use the XmlWriter class you'll generally follow these steps:
- Create an instance of XmlWriter in a script, storing it in a session variable.
- Extract data.
- In a script, get a reference to the XmlWriter object stored in step one, then call addElement or addElements to write out XML nodes.
- Repeat steps 2 and 3 as many times as you'd like.
- In a script, get a reference to the XmlWriter class, then call the close method on it.
The trickiest part is understanding which of the various addElement and addElements methods to call.
Examples
If you're scripting in Interpreted Java, the script in step 1 might look something like this:
// Note the forward slash (as opposed to a back slash after
// the "C:". This is a more Java-friendly way of handling the
// directory delimiter.
xmlWriter = new com.screenscraper.xml.XmlWriter( "C:/my_xml_file.xml", "root_element", "This is the root element" );
// Save the XmlWriter object in a session variable.
session.setVariable( "XML_WRITER", xmlWriter );
In subsequent scripts, you can get a reference to that same XmlWriter object like this:
You could then add elements and such to the XML file. The following three examples demonstrate the various ways to go about that. Each of the scripts are self-contained in that they create, add to, then close the XmlWriter object. Bear in mind that this process could be spread across multiple scripts, as described above.
Example 1
import com.screenscraper.xml.XmlWriter;
// Instantiate a writer with a root node named "simple-root".
XmlWriter xmlWriter = new XmlWriter("./simple.xml", "simple-root");
// Create four identical tags with different inner text.
for (int i = 0; i < 4; i++) {
// Appends to root element. No attributes.
xmlWriter.addElement( "one child", Integer.toString(i) );
}
// Close up the XML file.
xmlWriter.close();
This script would produce the following XML file:
<one_child>0</one_child>
<one_child>1</one_child>
<one_child>2</one_child>
<one_child>3</one_child>
</simple-root>
Example 2
import java.util.Hashtable;
import com.screenscraper.xml.XmlWriter;
// First set up the various attributes.
Hashtable attributes = new Hashtable();
attributes.put("attrib1", "1");
attributes.put("attrib2", "2");
attributes.put("attrib3", "3");
// These are the children we'll be adding.
Hashtable children = new Hashtable();
children.put("child1", "1");
children.put("child2", "2");
children.put("child3", "3");
children.put("child4", "4");
children.put("child5", "5");
// Instantiate a writer with a root node named "difficult-root".
XmlWriter xmlWriter = new XmlWriter("./difficult.xml", "difficult-root");
firstElement = xmlWriter.addElement("first child", "first child text", attributes);
// Add more info to the first element.
secondElement = xmlWriter.addElements(firstElement, "second child", "second child text", children);
// Add more elements to root. This time add text, attributes, and children.
thirdElement = xmlWriter.addElements("third child", "third child text", attributes, children);
// Illegal Example: Cannot add elements to the second Element
// since it was closed when thirdElement was added to the root.
// fourth = xmlWriter.addElement(secondElement, "wrong");
// Adds hashtable to attributes. Appends to root element.
fifth = xmlWriter.addElement("another", "test", attributes );
// Adds hashtable to children elements, appends to the fifth element.
sixth = xmlWriter.addElements(fifth, "other", "test2", children );
// Adds attributes and children. Appends to the sixth element.
seventh = xmlWriter.addElements(sixth, "complex", "example", attributes, children);
// Adds hashtable to attributes with children. Appends to root element.
eighth = xmlWriter.addElements("eight", "ocho", attributes, children );
// Close up the XML file.
xmlWriter.close();
This script would produce the following XML file:
<first_child attrib3="3" attrib2="2" attrib1="1">
first child text
<second_child>
second child text
<child5>5</child5>
<child4>4</child4>
<child3>3</child3>
<child2>2</child2>
<child1>1</child1>
</second_child>
</first_child>
<third_child attrib3="3" attrib2="2" attrib1="1">
third child text
<child5>5</child5>
<child4>4</child4>
<child3>3</child3>
<child2>2</child2>
<child1>1</child1>
</third_child>
<another attrib3="3" attrib2="2" attrib1="1">
test
<other>
test2
<child5>5</child5>
<child4>4</child4>
<child3>3</child3>
<child2>2</child2>
<child1>1</child1>
<complex attrib3="3" attrib2="2" attrib1="1">
example
<child5>5</child5>
<child4>4</child4>
<child3>3</child3>
<child2>2</child2>
<child1>1</child1>
</complex>
</other>
</another>
<eight attrib3="3" attrib2="2" attrib1="1">
ocho
<child5>5</child5>
<child4>4</child4>
<child3>3</child3>
<child2>2</child2>
<child1>1</child1>
</eight>
</difficult-root>
Example 3
import java.util.Hashtable;
import com.screenscraper.xml.XmlWriter;
Hashtable attributes = new Hashtable();
attributes.put("attrib1", "1");
attributes.put("attrib2", "2");
attributes.put("attrib3", "3");
// Create a new file (complex.xml) with a root element
// of 'complex-root' and text 'complex text'.
XmlWriter xmlWriter = new XmlWriter("./complex.xml", "complex-root", "complex text", attributes);
DataSet dataSet = new DataSet();
DataRecord dataRecord = null;
// Create 5 datarecords with different data.
for (int i = 0; i < 5; i++){
dataRecord = new DataRecord();
for (int j = 0; j < 5; j++) {
dataRecord.put("tag" + Integer.toString(j), Integer.toString(i * j));
}
dataSet.addDataRecord(dataRecord);
}
// Writes the data set to xml. The datarecords are surrounded by the tag
// defined by 'data set container'. Notice that the tag automatically
// reformats to: data_set_container, since xml tag names cannot have spaces.
xmlWriter.addElements("data set container", dataSet);
// Must be called after all writing is done. Will close the file and any
// open tags in the xml.<br />
xmlWriter.close();
This script would produce the following XML file:
<complex-root attrib3="3" attrib2="2" attrib1="1">
complex text
<data_set_container>
<tag4>0</tag4>
<tag3>0</tag3>
<tag2>0</tag2>
<tag1>0</tag1>
<tag0>0</tag0>
</data_set_container>
<data_set_container>
<tag4>4</tag4>
<tag3>3</tag3>
<tag2>2</tag2>
<tag1>1</tag1>
<tag0>0</tag0>
</data_set_container>
<data_set_container>
<tag4>8</tag4>
<tag3>6</tag3>
<tag2>4</tag2>
<tag1>2</tag1>
<tag0>0</tag0>
</data_set_container>
<data_set_container>
<tag4>12</tag4>
<tag3>9</tag3>
<tag2>6</tag2>
<tag1>3</tag1>
<tag0>0</tag0>
</data_set_container>
<data_set_container>
<tag4>16</tag4>
<tag3>12</tag3>
<tag2>8</tag2>
<tag1>4</tag1>
<tag0>0</tag0>
</data_set_container>
</complex-root>
Working with MySQL databases
Consider using the SqlDataManager as an alternative way to interact with your JDBC-compliant databases.
This example is designed to give you an idea of how to interact with MySQL, a JDBC-compliant database, from within screen-scraper.
You will need to have MySQL already installed and the service running.
To start, download the JDBC Driver for MySQL connector Jar file and place it in the lib/ext folder where screen-scraper is installed.
Next, create a script wherein you set the different values used to connect to your database. It is recommended that you call this script from your scraping session before scraping session begins.
// depending on your set up.
session.setVariable("MYSQL_SERVER_URL","localhost");
session.setVariable("MYSQL_SERVER_PORT","3306");
session.setVariable("MYSQL_DATABASE","mydb");
session.setVariable("MYSQL_SERVER_USER","username");
session.setVariable("MYSQL_SERVER_PASSWORD","password");
Create another script to set up your connection and perform queries on your database. Note, it is necessary to include the connection to your database within the same script as your queries.
You will be calling this script after you have extracted data. Typically this will either be after a scrapeable file runs or after an extractor pattern's matches are applied.
import java.sql.*;
//Set up a connection and a drivermanager.
Class.forName("com.mysql.jdbc.Driver").newInstance();
Connection conn;
conn = DriverManager.getConnection("jdbc:mysql://" + session.getVariable("MYSQL_SERVER_URL") + ":"+session.getVariable("MYSQL_SERVER_PORT") + "/" + session.getVariable("MYSQL_DATABASE"), session.getVariable("MYSQL_SERVER_USER"), session.getVariable("MYSQL_SERVER_PASSWORD"));
//Set extracted variables to local variables.
//Depending on when your script is executed
// you may have variables in session scope
// and others as dataRecords.
value1 = session.getVariable("value1");
value2 = session.getVariable("value2");
value3 = dataRecord.get("value3");
value4 = dataRecord.get("value4");
//Create statements and run queries
// on your database.
Statement stmt = null;
stmt = conn.createStatement();
mysqlstring="INSERT IGNORE INTO TABLE_NAME (column1, column2, column3, column4) VALUES('"+value1+"','"+ value2 + "','"+value3+"','" + value4 +"')";
stmt.executeUpdate(mysqlstring);
//Be sure to close up your
// statements and connection.
stmt.close();
conn.close();
Writing extracted data to a database
Overview
Oftentimes once you've extracted data from a page you'll want to write it to a database. Screen-scraper contains a special SqlDataManager class that makes this easy.
This script uses objects and methods that are only available in the professional and enterprise editions of screen-scraper.
To use the SqlDataManager class you'll generally follow these steps:
- To start, download the appropriate JDBC Driver connector Jar file for your particular database and place it in the lib/ext folder where screen-scraper is installed.
- Create an instance of SqlDataManager in a script.
- Build the database schema and any foreign key relations.
- Store the SqlDataManager in a session variable.
- Extract data.
- In a script, get a reference to the SqlDataManager object stored in step 3, then call addData to build the rows in your database tables.
- Once all data for a row has been added to the SqlDataManager object, call the commit method.
- After committing all data related to a record - which can include multiple rows across multiple tables, call the flush method to write the record to the database.
- Repeat steps 4 - 7 as many times as you'd like.
- In a script, get a reference to the SqlDataManager object, then call the close method on it.
The trickiest part is understanding when to call the commit method when writing to related tables.
Examples
If you're scripting in Interpreted Java and using a MySQL database, the script for steps 1-3 might look something like this:
import com.screenscraper.datamanager.sql.*;
import org.apache.commons.dbcp.BasicDataSource;
String hostpath = "localhost"; //Location of the database
String database = "database_name"; //The name of the database
String username = "your_username"; //Put your database username here
String password = "your_password"; //Put the password here
String port = "3306";
String dbparams = "autoReconnect=true&useCompression=true";
SqlDataManager dm;
try
{
// Connect to database using a BasicDataSource
BasicDataSource ds = new BasicDataSource();
ds.setDriverClassName( "com.mysql.jdbc.Driver" );
ds.setUsername( username );
ds.setPassword( password );
ds.setUrl( "jdbc:mysql://" + hostpath + ":" + port + "/" + database + "?" + dbparams );
ds.setMaxActive( 100 );
// Create Data Manager
dm = new SqlDataManager( ds, session );
dm.setLoggingLevel( org.apache.log4j.Level.DEBUG );
// Call this to have the data manager read information about the database, such as what tables exist,
// what fields they have, and how they relate to other tables in the database.
dm.buildSchemas();
// Setup the foreign key relationships, if needed
// If the database had this relationship built-in (InnoDB engine only), we wouldn't have to add this here.
// buildSchemas() would have added it when it read the database structure.
dm.addForeignKey( "child_table", "child_field", "parent_table", "parent_field" );
// Set the data manager to overwrite values in the table but not write NULL over values that are already there.
dm.setGlobalUpdateEnabled( true );
dm.setGlobalMergeEnabled( true );
// Save the SqlDataManager object in a session variable
session.setVariable( "_DBMANAGER", dm );
}
catch (Exception e)
{
session.logError( "Database initialization error" );
session.stopScraping();
}
Note that if you are using a database other the MySQL, the only change to this script will be the String passed to the setUrl method of the BasicDataSource.
In subsequent scripts, you can get a reference to that same SqlDataManager object like this:
You could then add data to the data manager. The following examples demonstrate various ways to go about that. Each of the scripts assume you already created an SqlDataManager object in a previous script and saved it to the session variable _DBMANAGER.
Saving to a single table using a data record
import com.screenscraper.datamanager.sql.SqlDataManager;
// Get the data manager from the session variable it is stored in
SqlDataManager dm = session.getVariable( "_DBMANAGER" );
// Add the current data record to the table.
// All values whose key in the data record match (case in-sensitive) a column in the table will be saved.
dm.addData( "people", dataRecord );
// Once all data has been added to the table, it should be committed
dm.commit( "people" );
// Flush the data so it is written to the database
dm.flush();
If the data record saved above had key-value pairs:
NAME = John Doe
AGE = 37
WEIGHT = 160
and the table 'people' had columns 'name', 'age', and 'gender', the script above would produce the following row in the people table.
| name | age | gender |
+----------+-----+--------+
| John Doe | 37 | NULL |
+----------+-----+--------+
Saving to a single table manually
import com.screenscraper.datamanager.sql.SqlDataManager;
// Get the data manager from the session variable it is stored in
SqlDataManager dm = session.getVariable( "_DBMANAGER" );
// Add data to the table.
dm.addData( "people", "name", "John Doe" );
dm.addData( "people", "age", "37" );
dm.addData( "people", "gender", session.getVariable("GENDER") );
// Once all data has been added to the table, it should be committed
dm.commit( "people" );
// Add another row of data to the table.
// As long as the previous data has been committed, this data will be added to a new row instead of overwriting previous data
dm.addData( "people", "name", "Sally Doe" );
dm.addData( "people", "gender", "female" );
// Flush the data so it is written to the database
dm.flush();
If the session variable GENDER had the value male and the table structure was the same as in the example above, this script would produce the following rows in the people table.
| name | age | gender |
+-----------+------+--------+
| John Doe | 37 | male |
+-----------+------+--------+
| Sally Doe | NULL | female |
+-----------+------+--------+
Note that you can mix the two methods shown above. Data can be added from multiple data records and/or manually for the same row.
Saving to multiple tables that are related.
This example assumes that you have a table in the database named people with fields 'id' (primary key/autoincrement), 'name', and 'address', and another table named phones with fields 'person_id', 'phone_number'.
Also, there is a foreign key relation between person_id in phones and id in people. This can be setup either in the database or when setting up the datamanger and calling the addForeignKey method.
In order to make it easier to see inserted values, all calls to addData in this example will enter data manually. In many cases, however, adding a data record is much easier.
Also, remember that data does not have to be added and committed all at once. Usually tables with a parent/child relation will have one script called after each pattern match of an extractor pattern that adds and commits a row of child data, and then a separate script called elsewhere to add and commit the parent data.
import com.screenscraper.datamanger.sql.SqlDataManager;
// Get the data manager from the session variable it is stored in
SqlDataManager dm = session.getVariable( "_DBMANAGER" );
// Add multiple phone numbers that will relate to John Doe
// Maybe he has a cell phone, home phone, and work phone
// After adding each row of data (simply a phone number in this case),
// commit the data so we can begin adding a new row.
dm.addData( "phones", "phone_number", "(123) 456-7890" );
dm.commit( "phones" );
dm.addData( "phones", "phone_number", "(800) 555-7777" );
dm.commit( "phones" );
dm.addData( "phones", "phone_number", "(333) 987-6543" );
dm.commit( "phones" );
// Now add the parent table's data and commit it
dm.addData( "people", "name", "John Doe" );
dm.addData( "people", "address", "123 Someplace Drv, Cityville, WY 12345" );
dm.commit( "people" );
// Add multiple phone numbers that will relate to Sally Doe
dm.addData( "phones", "phone_number", "(321) 654-0987" );
dm.commit( "phones" );
dm.addData( "phones", "phone_number", "(333) 987-6543" );
dm.commit( "phones" );
// Now add the parent table's data and commit it
dm.addData( "people", "name", "Sally Doe" );
dm.addData( "people", "address", "123 Someplace Drv, Cityville, WY 12345" );
dm.commit( "people" );
// Flush the data so it is written to the database
dm.flush();
Note the order in which tables were committed. All data in child tables must be committed before the data in the parent table.
This script would produce the following rows in the database:
| people |
+----+-----------+----------------------------------------+
| id | name | address |
+----+-----------+----------------------------------------+
| 1 | John Doe | 123 Someplace Drv, Cityville, WY 12345 |
+----+-----------+----------------------------------------+
| 2 | Sally Doe | 123 Someplace Drv, Cityville, WY 12345 |
+----+-----------+----------------------------------------+
+----------------------------+
| phones |
+-----------+----------------+
| person_id | phone_number |
+-----------+----------------+
| 1 | (123) 456-7890 |
+-----------+----------------+
| 1 | (800) 555-7777 |
+-----------+----------------+
| 1 | (333) 987-6543 |
+-----------+----------------+
| 2 | (321) 654-0987 |
+-----------+----------------+
| 2 | (333) 987-6543 |
+-----------+----------------+
The SqlDataManager takes care of filling in the data for the related fields. We never had to add the data for the person_id column in the phones table. Since id in people is an autoincrement field, we didn't have to add data for that field either.
Close the data manager
Once all data has been written to the database, close the data manager like this:
dm = session.getVariable( "_DBMANAGER" );
// Flushing the data here is optional, but if any data hasn't been written yet
// it will not be written when close() is called, and will be lost.
dm.flush();
// Close the datamanager
dm.close();
Automatically link many to many relations (Advanced)
The SqlDataManager can be set to automatically link data connected in a many-to-many relation. To enable this feature, use the following code:
When this setting is enabled, the data manager will attempt to relate data across multiple tables when possible. For example, if there is a people table, an address table, and a person_has_address table used to relate the other two tables, you would only need to insert data into the people and addresses tables. The data manager would then link the person_has_address table in since it has foreign keys relating it to both people and addresses. See the example below.
/*
Perform the setup of the SqlDataManager, as shown previously, and name the variable dm.
Also use a duplicate filter (see example below) to check for duplicate addresses
*/
// The setAutoManyToMany method must be called before any data is added to the data manager for the first time.
dm.setAutoManyToMany( true );
// Everything beyond this point might appear in a script other than the initialization script
dm.addData( "people", "name", "John" );
dm.addData( "addresses", "address", "123 Street" );
dm.commit( "addresses" );
dm.addData( "addresses", "address", "456 Drive" );
dm.commit( "addresses" );
dm.commit( "people" );
dm.addData( "people", "name", "Sally" );
dm.addData( "addresses", "address", "123 Street" );
dm.commit( "addresses" );
dm.commit( "people" );
This would produce the following result:
| people |
+-----------+-------+
| person_id | name |
+-----------+-------+
| 1 | John |
+-----------+-------+
| 2 | Sally |
+-----------+-------+
+-------------------------+
| addresses |
+------------+------------+
| address_id | address |
+------------+------------+
| 1 | 123 Street |
+------------+------------+
| 2 | 456 Drive |
+------------+------------+
+------------------------+
| person_has_address |
+-----------+------------+
| person_id | address_id |
+-----------+------------+
| 1 | 1 |
+-----------+------------+
| 1 | 2 |
+-----------+------------+
| 2 | 1 |
+-----------+------------+
Filtering Duplicate Entries (Advanced)
When extracting data that will contain many duplicate entries, it can be useful to filter values so that duplicate entries are not written to the database multiple times. The data manager can use a duplicate filter to check data being added to the database against data that is added, and either update or ignore duplicates. This is accomplished with an SqlDuplicateFilter object. To create a duplicate filter, call the SqlDuplicateFilter.register method, set the parent table it checks for duplicates on, and then add the constraints that indicate a duplicate. See the code below for an example of how to filter duplicates on a person table.
/*
Perform the setup of the SqlDataManager, as shown previously, and name the variable dm.
*/
//register an SqlDuplicateFilter with the DataManager for the social security number
SqlDuplicateFilter ssnDuplicate = SqlDuplicateFilter.register( "person", dm );
ssnDuplicate.addConstraint( "person", "ssn" );
//register an SqlDuplicateFilter with the DataManager for the drivers license number
SqlDuplicateFilter licenseDuplicate = SqlDuplicateFilter.register( "person", dm );
licenseDuplicate.addConstraint( "person", "drivers_license" );
//register an SqlDuplicateFilter with the DataManager for the name/phone number
//where the person table has a child table named phone.
SqlDuplicateFilter namePhoneDuplicate = SqlDuplicateFilter.register( "person", dm );
namePhoneDuplicate.addConstraint( "person", "first_name" );
namePhoneDuplicate.addConstraint( "person", "last_name" );
namePhoneDuplicate.addConstraint( "phone", "phone_number" );
Duplicate filters are checked in the order they are added, so consider perfomance when creating duplicate filters. If, for instance, most duplicates will match on the social security number, create that filter before the others. Also make sure to add indexes into your database on those columns that you are selecting by or else performance will rapidly degrade as your database gets large.
Duplicates will be filtered by any one of the filters created. If multiple fields must all match for an entry to be a duplicate, create a single filter and add each of those fields as constraints, as shown in the third filter created above. In other words, constraints added to a single filter will be ANDed together, while seperate filters will be ORed.
CAPTCHA User Input
Takes the session variable CAPTCHA_URL, generates a user input window, then saves the output to CAPTCHA_TEXT.
*/
import javax.swing.JOptionPane;
cfile = "captcha_image_" + System.currentTimeMillis();
session.log( "CAPTCHA_URL: " + session.getVariable("CAPTCHA_URL") );
session.log( "CAPTCHA image file: " + cfile );
session.downloadFile( session.getVariable( "CAPTCHA_URL" ), cfile );
imageIcon = new ImageIcon( cfile );
// Prompt the user for the text in the image.
response = JOptionPane.showInputDialog
(
null,
"Enter the text in the image",
"CAPTCHA Image",
JOptionPane.QUESTION_MESSAGE,
imageIcon,
null,
null
);
session.log( "User response: " + response );
session.setVariable( "CAPTCHA_TEXT", response );
imageIcon = null;
// Delete the image, now that we no longer need it.
new File( cfile ).delete();
System.gc();
Concatenate Strings from a DataRecord
This script is handy when the site you are scraping separates out a lot of pieces of information that you would like to put back together. For example, let's say you were searching for apartments, and the site you are scraping separates out the number of bedrooms, bathrooms, size of garage, number of living/family rooms, etc. You would like to be able to stick all of this information together into one string. To do this you need to concatenate all of the pieces from the session variables or dataRecord together like this:
//do some simple logic tests to make sure that the variable has something in it.
if( dataRecord.get("BEDROOMS")!=null ){
apartmentDetails = apartmentDetails + "Bedrooms: " + dataRecord.get("BEDROOMS").trim() + "|";
}
if( dataRecord.get("BATHROOMS")!=null ){
apartmentDetails = apartmentDetails + "Bathrooms: " + dataRecord.get("BATHROOMS").trim() + "|";
}
if( dataRecord.get("GARAGE")!=null ){
apartmentDetails = apartmentDetails + "Garage: " + dataRecord.get("GARAGE").trim() + "|"
}
//for the next example let's just assume that you had something in the session insead of in the dataRecord
if( session.getVariable("ADDRESS")!=null ){
apartmentDetails = apartmentDetails + "Address: " + session.getVariable("ADDRESS").trim() + "|";
}
//set the concatenated apartment details into a dataRecord Variable.
dataRecord.put ("APARTMENT_DETAILS", apartmentDetails);
While the above code isn't rocket science, hopefully the value of putting multiple strings together can be easy to see. Now pulling them apart again could be a little bit more troubling. :)
Debugging
Overview
There are times when you need to debug what is going on in your scrapes. The following can help with tracking down various issues.
Scrape Profiler
If a scrape is taking a long time, using the scrape profiler can help you see which scrapeable files and/or scripts are using all the time, so you could optimize their runtimes.
Another reason to consider using the scrape profiler is that there is a function to breakpoint when you overwrite a session variable, so similar to a breakpoint on variable change. Using this you can determine when a session variable is being overwritten when you don't expect it to be.
// This should be done in the very first script to run, right at the beginning (preferably in it’s own script)
ScrapeProfiler profiler = ScrapeProfiler.profileSession(session, false);
// Note that if you are trying to watch for a large stack of scripts or
// just want to see the state of things at any given point, you
// can call profiler.generateHtmlReport() at any point, which will
// return an HTML string you can then write to a file and view
// Once the scrape completes, it will generate an HTML file in your
// output directory, named "[scrapeName] - Profiling Data yyyy-MM-dd_HH_mm_ss_zz.html"
// (where the time values are the time the profiler was setup)
// which will contain data about each script, scrapeable file, extractor, etc...
// that shows execution times. These will be more accurate if the scrape
// ran for a while, as it tries to exclude the internal execution times
// meaning the percent time in each area won't add up to 100%
// Also you can have a breakpoint popup whenever a session variable
// is changed. Note this only works if the mapping is changed, not
// if something is changed in the variable itself. For example,
// if "Foo" is a map, and I call session.getVariable("Foo").put("x", "y")
// that won't trigger a breakpoint. However calling
// session.setVariable("Foo", "Something else") will trigger the
// breakpoint
profiler.setBreakpointOnSessionVariableChange("Foo");
Event Handler
The EventCallback method of the session provides many ways for you to attach listeners to various parts of your scrape enabling you to have even greater control as to what happens and when it comes to your scrapes.
Listed below are some examples on how to make use of this powerful class in addition you can check out the Session Profiler in the debugging section of the script repository to find more examples of using the Event Handler.
See Also
Example Resource Closer
// in which they were initialized
import com.screenscraper.events.*;
import com.screenscraper.events.session.*;
CsvWriter writer = new CsvWriter("output/my_csv_file.csv");
writer.setHeader(new String[]{"NAME", "ADDRESS"});
session.setVariable("_WRITER", writer);
// Setup a call to close the writer when the scrape ends (called regardless
// of whether the scrape was stopped mid run or completed normally)
EventHandler handler = new EventHandler()
{
public String getHandlerName()
{
return "Close resources";
}
public Object handleEvent(EventFireTime fireTime, SessionEventData data)
{
// Note that in the interpreter, directly referencing variables that
// were set external to the script (ie session, scrapeableFile, etc...)
// will cause an error. If they are needed, get them from the data object
data.getSession().logInfo("Closing resources...");
try
{
writer.close();
}
catch(Exception e)
{
// Do nothing
}
return data.getLastReturnValue();
}
};
// Set the event to be fired at a specific time
session.addEventCallback(SessionEventFireTime.AfterEndScripts, handler);
General Use
import com.screenscraper.events.*;
// Import the classes dealing with the events times you want to use
import com.screenscraper.events.session.*;
import com.screenscraper.events.scrapeablefile.*;
import com.screenscraper.events.script.*;
import com.screenscraper.events.extractor.*;
// Misc is random stuff that can be called from multiple locations
// and therefore didn't fit elsewhere
import com.screenscraper.events.misc.*;
// Create an EventHandler object which will be called when the event triggers
EventHandler handler = new EventHandler()
{
/**
* Returns the name of the handler. This method doens't need to be implemented
* but helps with debugging (on error executing the callback it will output this)
*/
public String getHandlerName()
{
return "A test event handler";
}
/**
* Processes the event, and potentially returns a useful value modifying something
* in the internal code
*
* @param fireTime The fire time of the event. This helps when using the same handler
* for multiple event times, to determine which was called
* @param data The actual data from the event. Based on the event time this
* will be a different type. It could be SessionEventData, ScrapeableFileEventData,
* ScriptEventData, StringEventData, etc... It will match the fire time class name
*
* @return A value indicating how to proceed (or sometimes the value is ignored)
*/
public Object handleEvent(EventFireTime fireTime, SessionEventData data)
{
// While you can specifically grab any data from the data object,
// if this is a method that has a return value that matters,
// it's best to get it as the last return value, so that multiple
// events can be chained together. The input data object
// will always have the original values for all the other getters
Object returnValue = data.getLastReturnValue();
// Do stuff...
// The EventFireTime values describe in the documentation what the return
// value will do, or says nothing about it if the value is ignored
// If you don't intend to modify the return, always return data.getLastReturnValue();
return returnValue;
}
};
// Set the event to be fired at a specific time
session.addEventCallback(SessionEventFireTime.AfterEndScripts, handler);
Modify Last Response
// on it. Perhaps we care about line breaks
import com.screenscraper.events.*;
import com.screenscraper.events.scrapeablefile.*;
import com.screenscraper.scraper.*;
// Setup a call on scrapeable files named "Details" to insert a
// <br /> tag everywhere there is a line break character
EventHandler handler = new EventHandler(){
public String getHandlerName()
{
return "Update last response with line breaks";
}
public Object handleEvent(EventFireTime fireTime, ScrapeableFileEventData data)
{
ScrapingSession session = data.getSession();
session.logInfo("Swapping out line breaks in the response for <br /> tags");
// We know for the event time this will trigger that this is a String
// and is the response data (post tidy) from the server
String response = data.getLastReturnValue();
response = response.replaceAll("(?s)\r?\n", "<br />\n");
// Return the new value, which will be used as the last response
return response;
}
};
// Set the event to be fired at a specific time. The documentation
// (as seen in the completion popup) tells us for this fire time
// the return value will be used as the response data
session.addEventCallback(ScrapeableFileEventFireTime.AfterHttpRequest, handler);
session.scrapeFile("Manually Scraped");
General Utility
Frequently there are tasks that you will perform on a regular basis. While you can write separate scripts for each of these, sometimes it is more useful to create an object that can store information to be used between scripts, much like an object in java. Below is general utility script that contains many useful functions. The first few hundred lines list the methods and what they are used for. The script is rather large (over 6500 lines), so please download it to view it.
The script is setup to create a Utility object when run, and store it in the session variable "_GENERAL_UTILITY". Generally when using this script, it should run before anything else. Then, to use it during the scrape it can be accessed by retrieving it from the session.
Example basic usage
// Remove anything that isn't a digit or decimal
// A number such as 5,678.77 would be returned as 5678.77
dataRecord.put("PRICE", util.formatNumber(dataRecord.get("PRICE"));
Example of advanced scrape monitoring
util = session.getVariable("_GENERAL_UTILITY");
// Set it to log the contents of all session variables that start with SEARCH_ each time it writes to the log
util.addMonitoredPrefix("SEARCH_");
// Also watch a specific session variable named WATCH_ME
util.addMonitoredVariable("WATCH_ME");
session.setVariable("DATASET", dataSet);
util.addMonitoredVariable("DATASET");
// Iterate over letters of the alphabet for a search on the site we are scraping
// and track the progress in the log
letterProgress = util.createProgressBar();
letterProgress.setTitle("Letters");
letterProgress.setTotal(26); // 26 letters to search
for(char c = 'a'; c <= 'z'; c++)
{
session.setVariable("SEARCH_LETTER", c);
session.scrapeFile("Search page");
// Increment the progress for the current letter search
letterProgress.add(1);
// Output a message to the log with the value of all currently monitored session variables
// and the progress (and estimated remaining scrape time).
// ** Note that when running in server mode and with enterprise edition, this will also output
// an easy-to-read message and progress bar in the web interface.
util.webMessage("Completed letter: " + c);
}
// Now that this loop is completed, remove the corresponding progress bar
util.removeProgressBar(letterProgress.getIndex());
// I like to end all my scrapes with a webClose() so the log ends with a snapshot of the values
// at the end of the scrape. This is just personal preference.
util.webClose("Scrape completed");
The output in the log from the above example would be something like the following, depending on the value of other variables that had been set.
=================== Log Variables with Message ===============
Completed letter: i
=================== Current Scrape Progress ===================
=== Letters: 34.61538461538461% (9.0 of 26.0) ===
5 minutes, 10 seconds, 201 ms, 543 ps, 902 ns
=================== Variables being monitored ===============
DATASET : DataSet
--- Record 0 : DataRecord
------ A_DATARECORD : DataRecord
--------- KEY : value in key
--------- KEY2 : value in key2
------ SOME_KEY : text
------ SOME_OTHER_KEY : other text
--- Record 1 : DataRecord
------ A_DATARECORD : DataRecord
--------- KEY : extracted data
--------- KEY2 : other data
------ SOME_KEY : 1
------ SOME_OTHER_KEY : other text
SEARCH_LETTER : i
WATCH_ME : null
================ End variables being monitored ==============
The monitored variables section tries to correctly output common types of data. For instance, DataSet and DataRecord objects are output as shown above with the DATASET variable. Other classes where similar output occurs are: List, Set, Map, and Exception. Also for Enterprise Edition, the a monitored ScrapeableFile will output in the web interface with a clickable link to view the URL with the same POST request as the file used. This will not set cookies, so the page may or may not display as expected.
Update
This script will periodically be updated with new functionality. Recently it was converted to a .jar file to increase the speed during execution. Because of this, if the jar version is not in the lib/ext directory of Screen-Scraper, an error will be logged when the script is run, but everything should still work. The error simply informs you that the script version is being run, and so it will not be as fast and may be missing a few features that could not be put in script form.
| Attachment | Size |
|---|---|
| GeneralUtility.jar | 236 KB |
Make a HEAD Request
On occasion rather than downloading an entire web page you may only want to know when it was last updated, or perhaps its content type. This can be done via an HTTP HEAD request (as opposed to a GET or POST). This script shows you how to go about that.
* This script allows you to retrieve a specific HTTP header
* from a server, such as the content-length (i.e., the size
* of the file).
*/
import org.apache.commons.httpclient.*;
import org.apache.commons.httpclient.methods.*;
import org.apache.commons.httpclient.params.HttpMethodParams;
import org.apache.commons.httpclient.contrib.ssl.EasySSLProtocolSocketFactory;
urlString = "http://www.google.com/";
// Create a method instance.
HeadMethod method = new HeadMethod( urlString );
// Provide custom retry handler is necessary
method.getParams().setParameter
(
HttpMethodParams.RETRY_HANDLER,
new DefaultHttpMethodRetryHandler( 3, false )
);
try
{
HttpClient client = new HttpClient();
session.setProxySettingsOnHttpClient( client, client.getHostConfiguration() );
try
{
HostConfiguration hostConfiguration = new HostConfiguration();
URL url = new URL( urlString );
if( url.toString().startsWith( "https" ) )
{
Protocol easyHTTPS = new Protocol( "https", new EasySSLProtocolSocketFactory(), 443 );
hostConfiguration.setHost( url.getHost(), 443, easyHTTPS );
}
else
{
hostConfiguration.setHost( url.getHost() );
}
}
catch( MalformedURLException mfue )
{
session.logError( "MalformedURLException: " + mfue, mfue );
}
// Execute the method.
int statusCode = client.executeMethod( method );
if( statusCode!=HttpStatus.SC_OK )
{
session.logError( "Error received status code: " + statusCode );
}
// Retrieve just the last modified header value.
String contentLength = method.getResponseHeader( "Content-Length" ).getValue();
session.log( "Content length: " + contentLength );
}
catch( Exception e )
{
session.logError( "An exception occurred: " + e.getMessage() );
}
finally
{
// Release the connection.
method.releaseConnection();
}
Pause Scrape at Specific Points
The following script is only 1 line of code. You may be thinking "Why would this script deserve a place in the repository?" and I'd answer, "I'll show you."
This code is called the breakpoint. When a script is being developed it is common to run it from inside of screen-scraper. In fact, it is a best practice to run scraping sessions often to ensure that you are getting the results you want by checking the log. It is during development that you might want to consider using this script.
First create a new script and label it breakpoint.
Then add this single line of code to it.
Now, when you want to check which variables are in scope you can include this script to run after a pattern is matched. This will come in very handy when you want to see what is in a dataRecord and what is saved as a session variable.
Then when your testing is done simply disable the script from running by removing the check mark in the enabled box wherever you have placed this script.
Repeatable scraping session
If you need your scraping session to run multiple times in succession, consider this script, which will repeat multiple times until it either hits the "quitTime" specified (24-hour clock), or when it hits the "maxRuns" allowed. To quickly (and dirtily) disable the "maxRuns" factor, set it to 0, or something negative. To disable the time restraint in "quitTime", just make sure it starts with something greater than or equal to 24 (for example, "24:00" or "123412:43").
String toRun = "first scrapeableFile name";
String quitTime = "14:43";
int maxRuns = 5;
/* No need to edit below here ----------------------------------- */
import java.text.SimpleDateFormat;
import java.util.Calendar;
if (quitTime.length() == 4)
quitTime = "0" + quitTime;
for (int i = 1; (new SimpleDateFormat("HH:mm")).format(Calendar.getInstance().getTime()).toString().compareTo(quitTime) < 0; i++)
{
session.scrapeFile(toRun);
if (i == maxRuns)
break;
}
Resume Scrape at Specified Point
The following script is useful in cases where you would like to restart a scrape from a specific point. It will generally be called from your "Search Results" page. This may come in handy if for some reason your scrape stops or breaks. Rather than starting your scrape over from the beginning, you may use this script to start scraping the "Details" page only after a value has been reached. This script may also be useful when you wish to skip to a point in the search results before proceeding onto the "Details" page. This script is an example of a scrape that stopped on Georgia, while scraping information from all 50 states. With this script in place, details will be scraped for every state after(and including) Georgia.
// You may wish to declare it in the initializing script at the beginning of the scrape.
// This if statement will set the "START" variable to the string "1"
// when your scrape has reached the appropriate "STATE" to beginning scraping
if (session.getVariable("STATE").equals("GEORGIA")){
session.setVariable("START", "1");
}
// Once the if statement above has evaluated to "true", the if statement below
// will also evaluate to "true" each time this script is called, and the "My Scrape--3 details"
// page will be called.
if (session.getVariable("START").equals("1")){
session.scrapeFile("My Scrape--3 details");
}
Note: If you are writing to a .csv file (say, using one of the "Write to File" scripts here in the script repository) the new values will be concatenated to the file.
Square Footage Catcher
This script was designed because while working for a client requesting building information, we needed to grab data about available square footage. Some targets sites had such sporatically formatted data that it was sometimes impossible to retrieve without a gauntlet of extractor patterns to catch every possible case of formatting. At times, the input was probably just a text box, so the user making the listing could have formatted the information however s/he wished, thus making it impossible to actually be able to guarantee that the pattern would match future listings.
So, although this script is huge, don't let it scare you. The point is that you save to a session variable (or to an in-scope dataRecord) the general region of a page. This region should predictably contain the square footage information, regardless of how its formatted. There are many optional variables that you may set to tweak the behavior of this script. Read about them in the header.
The idea here is to be able to pass a block of text/html from a page, and for this script to make heads or tails of it, and to save two variables: LISTING_MAX_SF and LISTING_MIN_SF.
(Sorry for the ugly formatting. The file is attached at the bottom of this post in a ".sss" format which you can import to screen-scraper, preserving the formatting.)
If you encounter any errors or problems, post comments here or on the forum for help. There could very well be cases that have gone untested in this script. We're looking to make it as robust as possible.
//////////////////////////////////////////////////////////////////////////
Retrieves text in the sessionVariable/dataRecord called "LISTING_MAX_SF". This will be processed and finally altered by the end of the script to
reflect the parsed data. "LISTING_MIN_SF" will also be set. By default, the script will return the data to the source type from which it found
"LISTING_MAX_SF". For example, if this script finds LISTING_MAX_SF in a dataRecord, it will overwrite the value in that dataRecord, and will
create a new entry in the dataRecord called "LISTING_MIN_SF".
Source priority: sessionVariable, dataRecord (again, by default, values will be returned automatically to the location from which the data was found.)
This script depends on:
* dataRecord / session variable "LISTING_MAX_SF" -- Contains a String of an entire body of text to parse. This variable is overwritten at the end of
each call to this script.
* session variable "SF_SPLIT_DELIMITER" -- see below.
This script can optionally accept values from:
* SF_IS_ACRES (anything) -- If this variable is set to anything other than null, the script will assume that you are working in acres,
and that you will need to convert your final numbers into SquareFootage for the BuildingSearch database. SF:Acres ratio is 43,560:1
* SF_RANGE_MARKER (String) -- A string of characters that will inform the script that a range is being encountered. This token
may contain a regular expression, as it is simply put into a java "replaceAll" call. Thus "(abcd|78|a|\\-)" would make the script
interpret all four terms as ways to notate a range (ie, "abcd", "78", "a", and "-" would all make the script try to find the
proposed range. The default rangeMarker "-" will be used if this variable is left undefined.
* SF_FORCE_NO_RANGE (anything) -- If this variable is set to anything other than null, range handeling will be disabled. This
may be useful if the default rangeMarker "-" is not desired at all.
* SF_SPLIT_DELIMITER (String) -- Same as "SF_RANGE_MAKER", except that this variable will actually be the token that will
divide the passed text in "LISTING_MAX_SF" to be split into an array. If this is left undefined, the splitting feature will be
totally disabled, and the script will parse the body of text as a single line. If SF_UNIT is left undefined in addition, then
the split delimiter will be forced to " " (single space), as each number in the text will need to be parsed. This is not a regular
expression.
* SF_UNIT (String) -- If there are extraneous numbers in the text, such that they are not followed by some unit that you would
like to limit results to, you may specify a regular expression that will predictably postfix the numbers that ARE in fact relevant.
It will be used for regex "lookahead". You must NOT include the digits that you are interested in matching.
Be sure to include potential whitespace between the number and the unit you would like to watch for.
Ex: a text containing " Suite 435: 800 SF" may find that setting "SF_UNIT" to "\\sSF" will be useful, as the script will
now ignore any numbers in the text that are not postfixed with the String found in "SF_UNIT". If SF_UNIT and SF_SPLIT_DELIMITER
are both left blank, SF_SPLIT_DELIMITER will be forced to " ".
* SF_NON_UNIT (String) -- Much like "SF_UNIT", except that this token will instead cause the script to ignore any numbers
postfixed by the String found in "SF_NON_UNIT". You must match the digits involved with the postfix, so include the "\\d" (or similar)
in the expression for the the script to properly dispose of them. This is simply done via a String.replaceAll(nonUnit, "") call.
Ex: a text containing "Parcel 4A - 250 acres" can be usefully parsed if "SF_NON_UNIT" is set to "\\d+[A-Z]" or
"[pP]arcel\\s\\d+\\s[A-Z]". The script will ignore matches found by the regular expressing found in this variable.
* SF_LITTER (String) -- A String that will define individual characters that are acceptably littering the numbers you would like to
preserve. For instance, numbers that contain "," or "." would require this variable to be set to ".," to tolerate numbers
that have commas and periods littered throughout the number. If left undefined, the script will automatically tolerate "," as a
valid littering character. Honestly, this doesn't really need to be manually defined very often. Only single characters are allowed.
If you write ".,moo" in this variable, the script will tolerate "." "," "m" "o" and "o", all separately. The effect would be achieved,
however the regex engine will not be matching "moo" as a single token.
* SF_DATA_PUTBACK (String) -- Must contain either "datarecord" or "sessionvariable". The script will auto-lowercase this String to
check it. Depending on the value thus contained, the script will put its final answers into the corresponding object. If anything
else other than the above specified values, the script will try to return the data to two session variables named as the contents of
this SF_DATA_PUTBACK variable, with a "_MIN_SF" and "_MAX_SF" postfix. For example, "TEMP_SF" will produce two variables called
"TEMP_SF_MIN_SF" and "TEMP_SF_MAX_SF".
* SF_DATA_GET (String) -- Must contain either "datarecord", "sessionvariable", an Integer (ie, 0, 24, etc, String or Integer) for
where to look to get the data we want to process. If an Integer, the script will look in the current dataSet at the index thus
supplied. If anything else other than the above specified values, the script will try to retrieve the data from a session variable
named as the contents of this SF_DATA_GET variable.
* SF_CALL_SCRIPT_A (String) -- The name of a script that you would like to execute before the script attempts to replace or split
anything in the variable "LISTING_MAX_SF". When this optional script is called, the variable itself has not yet been retrieved from
its source, so you may access and alter the "LISTING_MAX_SF" variable from the same source that you expect the variable to be retrieved
later in this script. Be sure to save any changes to the correct location (dataRecord or sessionVariable, etc)
* SF_CALL_SCRIPT_B (String) -- The name of a script that you would like to execute after the script has done basic splitting and
replaceAll calls. The data will be available in the "LISTING_MAX_SF" variable, and will now be an array, even if splitting did
not occur (ie, 'session.getVariable("LISTING_MAX_SF").length >= 1' at all times). You must place the postprocessed data back into
the sessionVariable "LISTING_MAX_SF" in order for the changes to be persistent.
*/
import java.util.regex.*;
import java.util.Hashtable;
import java.element.Util;
int putbackToDataSet = -1; // a variable used only when putting back to the dataSet
String body = null;
//\_/\_/\_/\// ERROR CHECKING FROM PUTBACK TYPE GIVEN IN "SF_DATA_PUTBACK"
// There's no need to error check if "SF_DATA_PUTBACK" wants to putback to a session variable
session.log("//\\_/\\_/\\_/\\// ============================");
String dataPutback = session.getVariable("SF_DATA_PUTBACK");
if (dataPutback != null) // if SF_DATA_PUTBACK was defined by the user
{
dataPutback = dataPutback.toLowerCase().replaceAll("[^a-z_]", "");
}
boolean noRange = false;
temp = session.getVariable("SF_FORCE_NO_RANGE");
if (temp != null)
noRange = true;
//\_/\_/\_/\// Optional script call to preprocess the data in LISTING_MAX_SF
if (session.getVariable("SF_CALL_SCRIPT_A") != null)
{
session.log("//\\_/\\_/\\_/\\// Executing variably called script: \"" + session.getVariable("SF_CALL_SCRIPT_A") + "\".");
session.executeScript(session.getVariable("SF_CALL_SCRIPT_A"));
session.log("//\\_/\\_/\\_/\\// Finished executing variably called script: \"" + session.getVariable("SF_CALL_SCRIPT_A") + "\".");
}
//\_/\_/\_/\// ERROR CHECKING FROM GET TYPE GIVEN IN "SF_DATA_GET"
String dataGet = session.getVariable("SF_DATA_GET"); // the source instructions, not the actual string to parse
if (dataGet != null) // if SF_DATA_GET was defined by the user
{
dataGet = dataGet.toLowerCase().replaceAll("[^a-z0-9_]", ""); // normalize the String
if (dataGet.equals("datarecord")) // if SF_DATA_GET wants to get from the dataRecord
{
body = dataRecord.get("LISTING_MAX_SF");
if (dataPutback == null) // if the putback variable was left undefined, then set it here
dataPutback = "dataRecord";
}
else if (dataGet.equals("sessionvariable"))
{
body = session.getVariable("LISTING_MAX_SF");
if (dataPutback == null) // if the putback variable was left undefined, then set it here
dataPutback = "sessionvariable";
}
else if (!dataGet.replaceAll("\\D", "").equals("")) // if SF_DATA_GET contained some digits
{
getFromDataSet = Integer.parseInt(dataGet.replaceAll("\\D", ""));
int numDataRecords= -1;
if (putbackToDataSet >= numDataRecords) // if the user set SF_DATA_GET to putback to a dataRecord that is too large for the in-scope dataSet
{
session.log("//\\_/\\_/\\_/\\// You've set SF_DATA_GET to retrieve its data from a dataRecord that is indexed too high (" + getFromDataSet + " when only " + numDataRecords + " exist). SF_DATA_GET begins its index at 0 and should be strictly less than the total number of dataRecords in the dataSet.");
session.log("//\\_/\\_/\\_/\\// ============================");
return;
}
}
else // else, we'll assume that the user wanted to pull from a session variable whose name is given by the string
{
body = session.getVariable(dataGet);
if (dataPutback == null)
dataPutback = dataGet; // if the dataPutback variable was left undefined, then track the "get" session variable name
}
}
else // if the user did not give a value for "SF_DATAGET"
{
session.log("//\\_/\\_/\\_/\\// Defaulting to sessionVariable \"LISTING_MAX_SF\" for input source. (See header of this script for notes on sessionVariable \"SF_DATA_GET\" if you wish to force the source.)");
if (session.getVariable("LISTING_MAX_SF") == null) // if no session variable is available...
{
session.log("//\\_/\\_/\\_/\\// sessionVariable \"LISTING_MAX_SF\" is null. Checking the dataRecord... (This will cause a script problem at line 130 if a dataRecord is not in scope.)");
body = dataRecord.get("LISTING_MAX_SF"); // ...then get it from the dataRecord (hopefully)
dataGet = "datarecord";
if (dataPutback == null) // ...and set the return type to also be dataRecord if it was also not specified
dataPutback = "datarecord";
}
else // if there is a valid session variable to read from...
{
body = session.getVariable("LISTING_MAX_SF"); // ...then get it from the session variable
dataGet = "sessionvaraible";
if (dataPutback == null) // and set the return type to also be sessionVariable if it was also not specified
dataPutback = "sessionvariable";
}
}
//\_/\_/\_/\// Make sure that have some text to parse, now that we have read from the source wanted in the user specification
if (body == null)
{ session.log("//\\_/\\_/\\_/\\// Error: No text was found in the specified parsing source. \"" + dataGet.toUpperCase() + "\". SF_DATA_GET might be set wrong, or not at all.");
session.log("//\\_/\\_/\\_/\\// ============================");
return;
}
String message = "";
if (session.getVariable("SF_DATA_PUTBACK") == null)
message = ", the source from which it was taken";
session.log("//\\_/\\_/\\_/\\// This execution of the script is set to return its parsed data into the " + dataPutback.toUpperCase() + message + ".");
//\_/\_/\_/\// Check in with the log
session.log("//\\_/\\_/\\_/\\// The text retrieved was \"" + body + "\".");
String[] bodySplit = null; // the array we'll split stuff into
//\_/\_/\_/\// prep for splitting
String splitDelimiter = session.getVariable("SF_SPLIT_DELIMITER");
if (splitDelimiter == null || splitDelimiter.equals(""))
splitDelimiter = "";
//\_/\_/\_/\// Prepare for possible SF_UNIT and SF_NON_UNIT usage
String unit = session.getVariable("SF_UNIT"); // things to watch for
String nonUnit = session.getVariable("SF_NON_UNIT"); // things to exlude
if (unit == null)
{
unit = ""; // if there's no unit supplied, we'll need to parse every number, so split on spaces
session.log("//\\_/\\_/\\_/\\// Warning: There was no unit supplied in \"SF_UNIT\", which will require that every number in the text is broken up for parsing.");
if (!splitDelimiter.equals(""))
session.log("//\\_/\\_/\\_/\\// Warning: Overriding the current split delimiter (\"" + splitDelimiter + "\") with a single space \" \"");
else
session.log("//\\_/\\_/\\_/\\// The split delimiter in \"SF_SPLIT_DELIMITER\" was blank, however, by circumstance, it must be set to \" \". The change will be made automatically, for this execution of the script only.");
splitDelimiter = " ";
}
if (nonUnit == null)
nonUnit = "";
//\_/\_/\_/\// Now we finally split, based on the splitting token possibly specified in "SF_RANGE_MARKER" and "SF_SPLIT_DELIMITER"
String rangeMarker = session.getVariable("SF_RANGE_MARKER");
if (!noRange) // If 'force range handeling' is off
{
if (rangeMarker == null) // If the user left the rangeMarker undefined...
rangeMarker = "-"; // ...then set the default
//\_/\_/\_/\// If we're going to split up the numbers to be detected as a range, we need to append the specified unit, if applicable.
// Replaces all range markers with the unit and splitDelimiter, so that it all gets split up once the call to body.split actually happens.
// This also exludes cases where there is a rangeMarker, yet no unit to propery accompany it, as in "666-55SF" when rangeMarker = "\\s+SF".
if (!unit.equals(""))
{
body = body.replaceAll("(?<=\\d)\\s*" + rangeMarker + "\\s*(?=\\d+" + unit + ")", unit.replaceAll("\\\\s[+*?]", " "));
session.log("//\\_/\\_/\\_/\\// After splitting up the range and appending the unit (regex definition: \"" + unit + "\"): " + body);
}
else
{
body = body.replaceAll(rangeMarker, splitDelimiter);
session.log("//\\_/\\_/\\_/\\// There was no unit supplied in \"SF_UNIT\", so splitting will occur over spaces and range markers. After splitting up ranges: " + body);
}
}
if (!unit.equals(""))
{
session.log("//\\_/\\_/\\_/\\// Set to find ranges around \"" + rangeMarker + "\".");
body = body.replaceAll(unit, unit.replaceAll("\\\\[sb][+*?]", " ") + splitDelimiter);
}
if (splitDelimiter.equals("") && !noRange) // happens with there IS a unit, but no split delimiter was supplied
{
bodySplit = body.split(rangeMarker);
}
else
{
session.log("//\\_/\\_/\\_/\\// Set to split on \"" + splitDelimiter + "\".");
bodySplit = body.split(splitDelimiter);
}
//\_/\_/\_/\// Place the new array back into the session variable (we're ignoring dataPutback here.. it doesn't matter for now), for optionally postprocessing the array
session.setVariable("LISTING_MAX_SF", bodySplit);
//\_/\_/\_/\// Optional script call to postprocess the data in LISTING_MAX_SF
if (session.getVariable("SF_CALL_SCRIPT_B") != null)
{
session.log("//\\_/\\_/\\_/\\// Executing variably called script: \"" + session.getVariable("SF_CALL_SCRIPT_B") + "\".");
session.executeScript(session.getVariable("SF_CALL_SCRIPT_B"));
session.log("//\\_/\\_/\\_/\\// Finished executing variably called script: \"" + session.getVariable("SF_CALL_SCRIPT_B") + "\".");
bodySplit = session.getVariable("LISTING_MAX_SF"); // this actually creates a reference to the changed array. This way, changes
// in the array.length are permitted, yet we can still use the same alias "bodySplit"
// later in the code.
}
// NOTE: we can't set that temp sessionVariable "LISTING_MAX_SF" storage to null yet, since it might be the data referred to by bodySplit.
// We'll clear it just before writing out to dataRecord, dataSet, or some other specified session variable other than "LISTING_MAX_SF"
//\_/\_/\_/\// Prepare for litter characters
String basicLitter = session.getVariable("SF_LITTER");
String litter = "";
if (basicLitter == null)
basicLitter = ",";
for (int j = 0; j < basicLitter.length(); j++)
litter += "|" + basicLitter.charAt(j);
basicLitter = null;<
//\_/\_/\_/\// Function declaration for use in the parsing loop section
// Strips the line down to only digits, and updates the min/max SF values
void finishAndUpdateMinMax(Hashtable SF, String line)
{
line = line.replaceAll("\\D", ""); // Destroys all remaining non-digits, leaving only the number(s) we're interested in
session.log("//\\_/\\_/\\_/\\// After eliminating all non-digits: " + line);
if (line.equals("") || Pattern.matches("\\s*", line))
{
session.log("//\\_/\\_/\\_/\\// No digits were found on this line.");
return;
}
float sfToken = Float.parseFloat(line);
if (SF.get("min") == 0 || sfToken < SF.get("min"))
SF.put("min", sfToken);
if (SF.get("max") == 0 || sfToken > SF.get("max"))
SF.put("max", sfToken);
}
//\_/\_/\_/\// Begin the actual parsing
// to hold our tracked Min and Max. I used a Hashtable so that I can pass it to functions and be able to alter it. (ie, it'll be passed by
// reference, as opposed to primitives, which are always passed by value.
Hashtable SF = new Hashtable();
SF.put("min", new Float(0)); // to track the local SF min
SF.put("max", new Float(0)); // to track the local SF max
for (int i = 0; i < bodySplit.length; i++)
{
String line = bodySplit[i];
if (!line.equals(""))
{
session.log("//\\_/\\_/\\_/\\// ----------------------------------------");
session.log("//\\_/\\_/\\_/\\// Processing: " + line);
if (!nonUnit.equals("")) // if the user specified a nonUnit that we should ignore, then zap it
{
line = line.replaceAll(nonUnit, "");
session.log("//\\_/\\_/\\_/\\// After ignoring non-units: " + line);
}
if (!unit.equals("")) // if we were given a unit to watch for, and if we found it in this line
{
Pattern p = Pattern.compile(unit); // Get a pattern going
Matcher m = p.matcher(line); // Link it with the line
if (m.find()) // Run it against the line
{
// This is magic. :) We match [digits or litters] that are NOT followed by our desired [digits or litters and then the unit]
// By doing this, we destroy all numbers that are not important to us, leaving only good numbers and other text
line = line.replaceAll("(\\d" + litter + ")(?!(\\d" + litter + ")*" + unit + ")", "");
session.log("//\\_/\\_/\\_/\\// After allowing only numbers with specified unit \"" + unit + "\": " + line);
// Test for a more matches in the line
if (m.find())
session.log("found another one.");
finishAndUpdateMinMax(SF, line);
}
else
{
session.log("//\\_/\\_/\\_/\\// This line does not contain the specified unit \"" + unit + "\".");
}
}
else
{
finishAndUpdateMinMax(SF, line);
}
}
}
session.log("//\\_/\\_/\\_/\\// ============================");
if (SF.get("max") == 0) // If the parse yielded no results
{
SF.put("min", 0);
session.setVariable("LISTING_MAX_SF", null);
session.setVariable("_LISTING_MODIFIABLE", "FALSE"); // If there's no available room, then don't insert it into the database.
session.log("//\\_/\\_/\\_/\\// Warning: A zero was determined to be the largest number in the text. This listing will not be inserted.");
session.log("//\\_/\\_/\\_/\\// ============================");
return;
}
//\_/\_/\_/\// Convert from SF to acres if needed
if (session.getVariable("SF_IS_ACRES") != null)
{
session.log("//\\_/\\_/\\_/\\// Variable \"SF_IS_ACRES\" is set. Numbers will now be converted to square feet from acres.");
SF.put("min", SF.get("min") * 43560);
SF.put("max", SF.get("max") * 43560);
}
//\_/\_/\_/\// Put the data back where the user wants it
String varName = "LISTING";
if (dataPutback.equals("dataRecord")) // If we want to putback to the dataRecord in scope
{
session.log("//\\_/\\_/\\_/\\// Putting the data into the current DATARECORD as:");
dataRecord.put(varName + "_MIN_SF", SF.get("min").intValue().toString());
dataRecord.put(varName + "_MAX_SF", SF.get("max").intValue().toString());
session.setVariable("LISTING_MAX_SF", null); // we used this as a temp variable earlier. If the user wants to putback to the dataRecord,
// then we don't want this temp value to persist.
}
else if (dataPutback.equals("sessionvariable")) // If we want to putback to the "LISTING_MIN_SF" and "LISTING_MAX_SF" session variables
{
session.log("//\\_/\\_/\\_/\\// Putting the data into SESSIONVARIABLES as:");
session.setVariable(varName + "_MIN_SF", SF.get("min").intValue().toString());
session.setVariable(varName + "_MAX_SF", SF.get("max").intValue().toString());
}
else // If we want to putback to custom sessionVariable names + "_MIN_SF"/"_MAX_SF"
{
varName = dataPutback;
session.log("//\\_/\\_/\\_/\\// Putting the data into SESSIONVARIABLES as: \"" + dataPutback + "_MIN_SF\" and \"" + dataPutback + "_MAX_SF\".");
session.setVariable(varName + "_MIN_SF", SF.get("min").intValue().toString());
session.setVariable(varName + "_MAX_SF", SF.get("max").intValue().toString());
session.setVariable("LISTING_MAX_SF", null); // we used this as a temp variable earlier. If the user wants to putback to the dataRecord,
// then we don't want this temp value to persist.
}
session.log("//\\_/\\_/\\_/\\// " + varName + "_MIN_SF: " + SF.get("min").intValue().toString());
session.log("//\\_/\\_/\\_/\\// " + varName + "_MAX_SF: " + SF.get("max").intValue().toString());
session.log("//\\_/\\_/\\_/\\// ============================");
| Attachment | Size |
|---|---|
| SF (Script).sss | 22.06 KB |
String Tokenizer
The content of the following script is very similar to some other scripts in the repository. The tokenizer takes a string and breaks it into smaller strings at every space. So if I had a sentence like: "the answer is 42" the tokenizer would give me an array of strings like this:
the
answer
is
42
Broken on every space.
in this example a state is seperated by a zip with only a space between them.
tokenizer = new StringTokenizer(stateZip);
//the first token goes into the state
state = tokenizer.nextToken();
//the second token is the Zip
zip = tokenizer.nextToken();
//now put them into their dataRecord Variables
dataRecord.put("STATE",state);
dataRecord.put("ZIP",zip);
//print out to the log so you can see the values.
session.log("STATE=" + dataRecord.get("STATE"));
session.log("ZIP=" + dataRecord.get("ZIP"));
Use Async client
Required version
6.0.63a or newer
Usage
Invoke the script at the beginning of the scrape to use the Async client for HTTP connections