Anonymization
Overview
Under certain circumstances you may want to anonymize your scraping so that the target site is unable to trace back your IP address. For example, this might be desirable if you're scraping a competitor's site, or if the web site blocks IP addresses that make too many requests.
There are a few different ways to go about this using screen-scraper:
If you choose to run anonymous scripts from an external script, it is valuable to read through the documentation on controlling anonymization externally.
Aside from the above methods, you might find our blog posting on how to surf and screen-scrape anonymously helpful. It's slightly dated, but still very relevant.
Automatic Anonymization
Overview
The screen-scraper automatic anonymization service works by sending each HTTP request made in a scraping session through a separate high-speed HTTP proxy server. The end effect of this is that the site you're scraping will see any request you make as coming from one of several different IP addresses, rather than your actual IP address. These HTTP proxy servers are actually virtual machines that get spawned and terminated as you need them. You'll use screen-scraper to either manually or automatically spawn and terminate the proxy servers.
Steps to take
- Request an Anonymization account
- Pay set up fee
- Enter your anonymization password
- Check the "anonymize this scraping session" checkbox
- Run your scraping session
Cost
- $150 setup
- 25 cents per proxy per hour
Note: When using the automatic anonymization method, while the remote web site may not be able to determine your IP address, your activity will still be logged. If you attempt to use the proxy service for any illegal activities, the chances are very good that you will be prosecuted.
Limitations
While the automatic anonymization service provides an excellent way to cloak your IP address it is still possible that the target web site will block enough of the anonymized IP addresses that the anonymization could fail. Unfortunately we can't make any guarantees that you won't get blocked; however, by using the automatic anonymization service the chances of getting blocked are reduced dramatically.
Miscellaneous
- Anonymization REST Interface
- Workbench Interface: Scraping Session: Anonymization tab
- AnonymousProxyPassword: The password that you were sent.
- AnonymousProxyAllowedIPs: The IP addresses permitted to access anonymous sessions.
- AnonymousProxyMaxRunning: Maximum number of proxy servers used to do the scrape.
- AnonymizationURLPrepend: Which server to use for anonymization. By default http://anon.screen-scraper.com will be used.
Acceptable values are http://anon.screen-scraper.com and http://anon2.screen-scraper.com.
Automatic Anonymization: Setup
Controlling your Account
The anonymous proxy servers will be set up in such a way that they only allow connections from your IP address. This way no one else can use any of the proxies without your authorization. This configuration is tied to your password. For more on restricting connections see documentation on managing the screen-scraper server.
If you'll be running your anonymized scraping sessions on the same machine (or local network) you're currently on and you are using the workbench, you can click the Get the IP address for this computer button to determine your current IP address.
screen-scraper Setup
Using Workbench
Anonymization settings can be configured using screen-scraper's workbench. Settings are determined in the anonymous proxy settings of the settings dialog box.
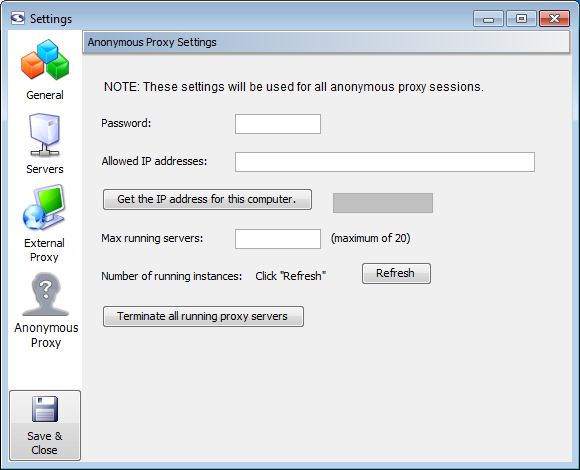
When you sign up for the anonymization service you'll be given the password that allows your instance of screen-scraper to manage anonymous proxies for you. You'll enter it into the Password textbox in the settings.
As the proxy servers get spawned and terminated, it's a good idea to establish the maximum number of running proxy servers you'd like to allow. This is done via the Max running servers setting. Because you pay for proxy servers by the hour, if you don't have your scraping session set up to automatically shut them down at the end, you'll use the Terminate all running proxy servers button in order to do that.
We find that as many as 10 proxy servers but no fewer than five are adequate for most situations.
Using screen-scraper.properties File
If you're setting this value in a GUI-less environment (i.e., a server with no graphical interface), you'll want to set these values in the resource/conf/screen-scraper.properties file (if these property is not already in the file you'll want to add it).
Be sure to modify the resource/conf/screen-scraper.properties file only when screen-scraper is not running.
Scraping Session Setup
Aside from these global settings, there are a few settings that apply to each scraping session you'd like to anonymize. You can edit these settings under the anoymization tab of your scraping session.
Once you've configured all of the necessary settings, try running your scraping session to test it out. You'll see messages in the log that indicate what proxy servers are being used, how many have been spawned, etc.
As your anonymous scraping session runs, you'll notice that screen-scraper will automatically regulate the pool of proxy servers. For example, if screen-scraper gets a timed out connection or a 403 response (authorization denied), it will terminate the current proxy server, and automatically spawn a new one in its place. This way you will likely always have a complete set of proxy servers, regardless of how frequently the target web site might be blocking your requests. You can also manually report a proxy server as blocked by calling session.currentProxyServerIsBad() in a script. When this method is called the current proxy server will be shut down and replaced by another.
Anonymization via Manual Proxy Pools
Overview
If the automatic anonymization method isn't right for you, the next best alternative might be to manually handle working with screen-scraper's built-in ProxyServerPool object. The basic approach involves running a script at the beginning of your scraping session that sets up the pool, then calling session.currentProxyServerIsBad() as you find that proxy servers are getting blocked. In order to use a proxy pool, you'll also need to get a list of anonymous proxy servers. Generally you can find these by Googling around a bit.
See available methods:
ProxyServerPool
Anonymization API
Example
// Create a new ProxyServerPool object. This object will
// control how screen-scraper interacts with proxy servers.
proxyServerPool = new ProxyServerPool();
// We give the current scraping session a reference to
// the proxy pool. This step should ideally be done right
// after the object is created (as in the previous step).
session.setProxyServerPool( proxyServerPool );
// This tells the pool to populate itself from a file
// containing a list of proxy servers. The format is very
// simple--you should have a proxy server on each line of
// the file, with the host separated from the port by a colon.
// For example:
// one.proxy.com:8888
// two.proxy.com:3128
// 29.283.928.10:8080
// But obviously without the slashes at the beginning.
proxyServerPool.populateFromFile( "proxies.txt" );
// screen-scraper can iterate through all of the proxies to
// ensure theyre responsive. This can be a time-consuming
// process unless it's done in a multi-threaded fashion.
// This method call tells screen-scraper to validate up to
// 25 proxies at a time.
proxyServerPool.setNumProxiesToValidateConcurrently( 25 );
// This method call tells screen-scraper to filter the list of
// proxy servers using 7 seconds as a timeout value. That is,
// if a server doesnt respond within 7 seconds, it's deemed
// to be invalid.
proxyServerPool.filter( 7 );
// Once filtering is done, it's often helpful to write the good
// set of proxies out to a file. That way you may not have to
// filter again the next time.
proxyServerPool.writeProxyPoolToFile( "good_proxies.txt" );
// You might also want to write out the list of proxy servers
// to screen-scraper's log.
proxyServerPool.outputProxyServersToLog();
// This is the switch that tells the scraping session to make
// use of the proxy servers. Note that this can be turned on
// and off during the course of the scrape. You may want to
// anonymize some pages, but not others.
session.setUseProxyFromPool( true );
// Check number of available proxies
if (proxyServerPool.getNumProxyServers() < 4)
{
// As a scrapiing session runs, screen-scraper will filter out
// proxies that become non-responsive. If the number of proxies
// gets down to a specified level, screen-scraper can repopulate
// itself. Thats what this method call controls.
proxyServerPool.setRepopulateThreshold( 5 );
}
That's about all there is to it. Aside from occasionally calling session.currentProxyServerIsBad(), you may also want to call session.setUseProxyFromPool to turn anonymization on and off within the scraping sesison.