4: Create Extractor Pattern
This is probably the trickiest part of the tutorial, so if you've been skimming up to this point you'll probably want to read this page a little more carefully. Here we are going to discuss extractor patterns.
What is an Extractor Pattern?
An extractor pattern is a block of text (usually HTML) that contains special tokens that will match the pieces of data you're interested in gathering. These tokens are text labels surrounded by the delimiters ~@ and @~.

You can think of an extractor pattern like a stencil. A stencil is an image in cut-out form, often made of thin cardboard. To use a stencil you place it over a piece of paper, apply paint, then remove the stencil. The effect is the paint only remains where there were holes in the stencil. Analogously, you can think of placing an extractor pattern over the HTML of a web page. The tokens correspond to the holes where the paint would pass through. After an extractor pattern is applied it reveals only the portions of the web page where tokens were added.

Creating an Extractor Pattern (conceptually)
Let's consider this snippet of HTML that was taken from the page:
As we're interested in extracting the string "Hello world!" our extractor pattern would look like this:
We have added an extractor token with the name FORM_SUBMITTED_TEXT. In this form the pattern is very exact and so prone to breaking if the page were to experience a minor change like adding another attribute to the span tag, changing the style attribute to a class assignment, or changing the tag that is used. To avoid these simple problems we will simplify our pattern.
As you can guess this does not make the pattern unbreakable, just more resilient. If the label before the submitted text was changed it would no longer match and if the pattern added something after the submitted text (but within the same tag) then the token would match too much. That said, we have made it as stable as we can while making sure that it only matches what we want.

Creating an Extractor Pattern
You can have as many extractor patterns as you'd like in a given scrapeable file. screen-scraper will invoke each of them in sequence after requesting the scrapeable file.
The last response tab can be used to create extractor patterns using the HTML of the page. To view the HTML of the page, click on the Form submission scrapeable file, then on the Last Response tab. Now select the portion of the HTML that we want to use to create the extractor pattern:
If you are having trouble finding it you can use the Find button.
With the text selected, right click and select Generate extractor pattern from selected text from the menu that shows up. This will transition you to the Extractor Patterns tab of the scrapeable file and place the selected text in the Pattern text field.
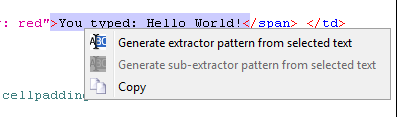
Now highlight the text that you want to be a token:
With the text selected, right click and select Generate extractor pattern token from selected text.

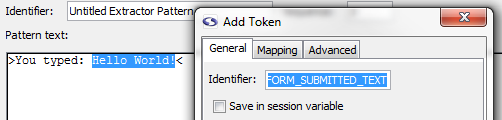
In the window that opens type FORM_SUBMITTED_TEXT in the Identifier textbox and close the window by clicking on the X in the upper right-hand corner. Don't worry settings are saved when the window closes.
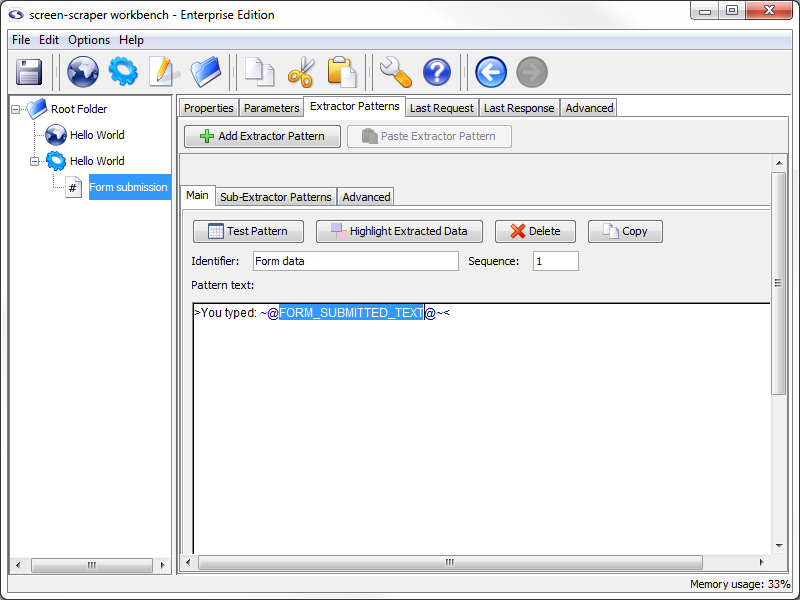
You will notice that screen-scraper has automatically added the delimiters (~@ and @~) to the extractor token.

Give your extractor pattern the identifier
When creating an extractor pattern it is always preferable to use the text in the Last Response tab. When the page gets too long the text will be truncated. This will require you to view to the page source instead, this introduces possible issues. Be careful creating extractor patterns from the browser source as this will not be the exact form that screen-scraper will be using. Test the pattern early and often.

Testing the Extractor Pattern
Go ahead and give the extractor pattern a try by clicking on the Test Pattern button. This will open a window displaying the text that the extractor pattern extracted from the page.

Looks like our extractor pattern has matched the snippet of text we were after. The Test Pattern is another invaluable tool you'll use often to make sure you're getting the right data. It simply uses the HTML from the Last Response tab, and applies the extractor pattern to it.
When creating extractor patterns, always be sure you use the HTML from screen-scraper's Last Response tab, and not the HTML source in your web browser. Before screen-scraper applies an extractor pattern to an HTML page, it tidies up the HTML to facilitate extraction. This will generally cause the HTML to be slightly different from the HTML you'd get directly from your web browser.
Save Extractor Token values to Session Variable
Click the Save in session variable checkbox to store the extracted value ("Hello World!") represented by the FORM_SUBMITTED_TEXT Extractor Pattern Token.
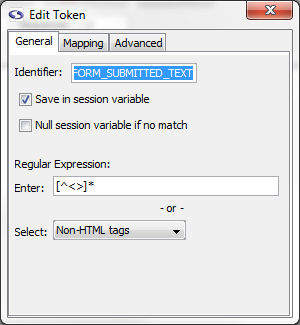
Close the Edit Token window. Now when screen-scraper runs this scraping session and extracts the text for this extractor pattern it will save the text (e.g., "Hello world!") in a session variable so that we can do something with it later. Let's do something with it.