Iteration
Overview
One of the most common things to need is the ability to iterate over the results of a search. This usually requires the ability to iterate over the same page with changes to the parameters that are passed. There are examples of this in the second and third tutorials.
There are different methods to use and one thing to keep in mind: memory. This is especially important on larger scrapes and for basic users where the number of scripts on the stack needs to be watched. Below are some examples of Next Page scripts. Which you choose to use will depend on what is available and what your needs are.
Memory Conscious Next Page
If you're scraping a site with lots of "next page" links, you are well advised to use the following script, instead of the other two listed here.
Conceptually, the problem with calling a script at the end of a scrapeableFile, which calls the same scrapeableFile over and over again, is that you're stacking the scrapeableFiles on top of one another. They'll never leave memory until the last page has completed, at which point the stack quickly goes away. This style of scraping is called "recursive".
If you can't predict how many pages there will be, then this idea should scare you :) Instead, you should use an "iterative" approach. Instead of chaining the scrapeableFiles on the end of one another, you call one, let it finish and come back to the script that called it, and then the script calls another. A while/for loop is very fit for this.
Here's a quick illustration of a comparison, so that you can properly visualize the difference. Script code to follow.
search results for category "A"
|- next results
|- next results
|- next results
|- next results
search results for category "B"
|- next results
|- next results
|- next results
|- next results
|- next results
|- next results
// Now here's the for-loop "iterative" approach, via a single control script:
search results for category "A"
next results
next results
next results
next results
search results for category "B"
next results
next results
next results
next results
next results
next results
Much more effective.
So here's how to do it. When you get to the point where you need to start iterating search results, call a script which will be a little controller for the iteration of pages. This will handle page numbers and offset values (in the event that page iteration isn't using page numbers).
First, your search results page should match some extractor pattern which hints that there is a next page. This helps remove what the page number actually is, and reduces next pages to a simple boolean true or false. The pattern should match some text that signifies a next page is present. In the example code below, I've named the variable "HAS_NEXT_PAGE". Be sure to save it to a session variable. If there is no next page, then this variable should not be set at all. That will be the flag for the script to stop trying to iterate pages.
int initialOffset = 0;
// ... and this number is the amount that the offset increases by each
// time you push the "next page" link on the search results.
int offsetStep = 20;
String fileToScrape = "Search Results ScrapeableFile Name";
/* Generally no need to edit below here */
hasNextPage = "true"; // dummy value to allow the first page to be scraped
for (int currentPage = 1; hasNextPage != null; currentPage++)
{
// Clear this out, so the next page can find its own value for this variable.
session.setVariable("HAS_NEXT_PAGE", null);
session.setVariable("PAGE", currentPage);
session.setVariable("OFFSET", (currentPage - 1) * offsetStep + initialOffset);
session.scrapeFile(fileToScrape);
hasNextPage = session.getVariable("HAS_NEXT_PAGE");
}
The script provides to you a "PAGE" session variable, and an "OFFSET" session variable. Feel free to use either one, whichever your situation calls for.
OFFSET will (given the default values in the script), be 0, 20, 40, 60, etc, etc.
PAGE will be 1, 2, 3, 4, 5, etc, etc.
Next Page Link
The following script is called upon completion of scraping the first page of a site's details. This script is useful when matching the current page number in the HTML is preferable or simpler than matching the next page number. Depending on how a site is coded, the number of the next page may not even appear on the current page. In this case, we would match for the word "Next", to simply determine if a next page exists or not. The regular expression used for the word next would be used as follows:
The regular expression for the lone token ~@NEXT@~ would be the text that suggests that a next page exists, such as Next Page or maybe a simple >> link.
The only change you should have to make to the code below is to set any variable names properly (if different than in your own project), and to set the correct scrapeableFile name near the bottom.
// Check to see if we found the word or phrase that flags a "Next" page
if (session.getVariable("NEXT") != null)
{
// Retrieve the page number of the page just scraped
currentPage = session.getVariable("PAGE");
if (currentPage == null)
currentPage = 1;
else
currentPage = Integer.parseInt(currentPage).toString();
// write out the page number of the page just scraped
session.log("Last page was: " + currentPage);
// Increment the page number
currentPage++;
// write out the page number of the next page to be scraped
session.log("Next page is: " + currentPage);
// Set the "PAGE" variable with the incremented page number
session.setVariable("PAGE", currentPage);
// Clear the "NEXT" variable so that the next page is allowed to find it's own value for "NEXT"
session.setVariable("NEXT", null);
// Scrape the next page
session.scrapeFile("Scraping Session Name--Next Page");
}
Simple Next Page
One of our fellow contributors of this site posted a Next Page script which can be very useful, but may be more code than what you might need. Because every site is constructed differently, iterating through pages can be one of the most difficult parts for a new screen-scraper to master. Indeed, the design of how to get from page to page typically takes some creativity and precision.
One initial word of warning about going from page to page. Occasionally a site will be designed so you can get to the next page at the top and the bottom of the current page. Everybody has seen these before. For example, you're looking through a site which sells DVDs and at the top and the bottom of the list there is a group of numbers that shows what page you are currently viewing, the previous page, the next page, and sometimes the last page. The problem occurs when your pattern matches for the next page before you get to the data you want extracted. If that is the case, your session begins to flip through pages at a very fast rate without retrieving any information at all! Do yourself a favor and match for the one at the bottom of the page.
After you have a successful match, the following script can be applied "Once if pattern matches".
We realize that it is only one line of code, but in many cases that is all that it needs to be.
Iterate over DataSets & DataRecords
myDataRecord = new DataRecord();
if (session.getVariable("A") != null && session.getVariable("A") != "")
{
myDataRecord.put("A",session.getVariable("A"));
}
if (session.getVariable("B") != null && session.getVariable("B") != "")
{
myDataRecord.put("B",session.getVariable("B"));
}
if (session.getVariable("C") != null && session.getVariable("C") != "")
{
myDataRecord.put("C",session.getVariable("C"));
}
dataSet.addDataRecord( myDataRecord );
session.log("how many fields in myDataRecord? " + myDataRecord.size());
int totalValues = 0;
for (int i=0; i<dataSet.getNumDataRecords(); i++)
{
dr = dataSet.getDataRecord(i);
enumeration = dr.keys();
while (enumeration.hasMoreElements())
{
key = enumeration.nextElement();
value = dr.get(key);
session.log("key:value **" + key + ":" + value + "**");
totalValues += Integer.parseInt(value).intValue();
}
}
session.log("Sum of all values for this dataRecord: " + totalValues);
session.log("Average of the sum of all values: " + (totalValues / dr.size()));
// Remove all DataRecord objects from the dataSet object.
dataSet.clearDataRecords();
Manual Data Extraction
A sub-extractor pattern can only match one element but manual data extraction allows you to give the same additional context information as using a sub-extractor pattern but allows you the ability to extract multiple data records.
This example makes use of the extractData() method.
The code and examples below demonstrate how to first isolate and extract a portion of a page's total HTML, so that a second extractor pattern may then be applied to just the extracted portion. Doing so can limit the results to only those found on a specific part of the page. This can be useful when you have 100 apples that all look the same but you really only want five of them.
The following screen shots show an example of when the script above might be used. In this example, we are only interested in the active (shown with green dots) COMPANY APPOINTMENTS, and not the LICENSE AUTHORITIES (sample HTML available at the end).
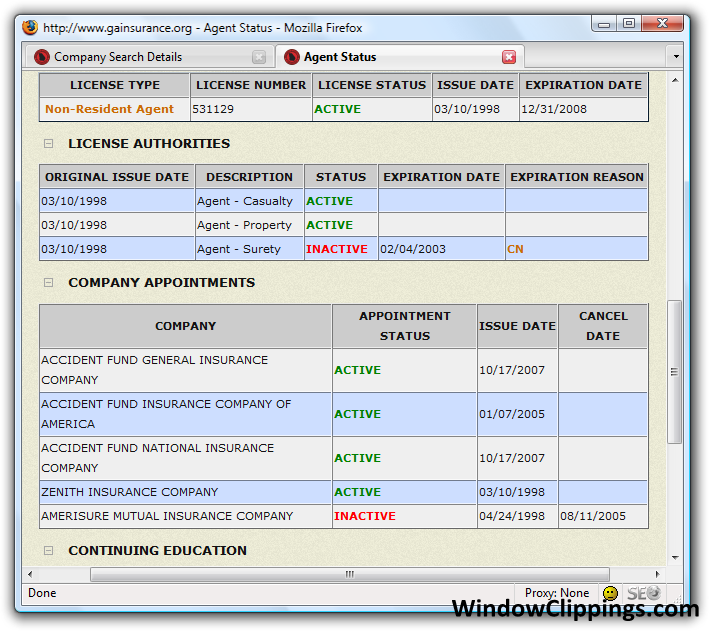
When applied to the all of the HTML of the current scrapeable file, the following extractor pattern will retrieve ALL of the html that makes up the COMPANY APPOINTMENTS table above. But, remember, we only want the active appointments.
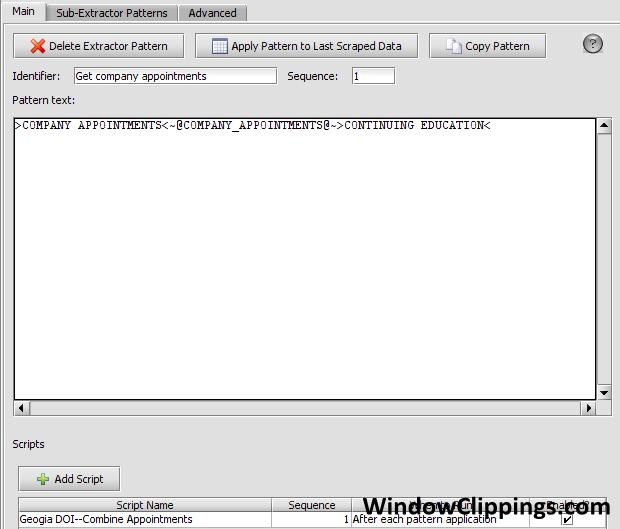
//Create a local variable called appointments to store the dataset that is generated when you
//MANUALLY apply the "Appointments" extractor pattern to the already extracted data that
//resulted from the application of the COMPANY_APPOINTMENTS extractor pattern.
DataSet appointments = scrapeableFile.extractData(dataRecord.get("COMPANY_APPOINTMENTS"), "Appointments");
// ^^token name^^ ^^extractor id^^
// Start the local variable allAppointments where we will one-by-one append the values of each
//matching appointment. Separate them with the pipe character "|".
allAppointments = "";
// Take the appointments dataSet generated from above and loop through
//each of the successful matches that are stored as records.
for (i=0; i < appointments.getNumDataRecords(); i++)
{
// Grab the current dataRecord from the looping dataSet
appointmentRecord = appointments.getDataRecord(i);
// Grab the results of the applied ~@APPOINTMENT@~ token
// referencing it by name.
// Note: it's possible to reference more than one token here
appointment = appointmentRecord.get("APPOINTMENT");
// Append the current appoinment to the growing list of matches
allAppointments += appointment + " | ";
}
// When the loop is done, store the results in a session variable
session.setVariable("APPOINTMENTS", allAppointments);
// Write them out to log to see if they look right
session.log("The appointments are: " + allAppointments);
<div id="Level3" style="Display: Block; position: relative; text-align: center">
<table class="verysmalltext" width="90%" border="1" cellpadding="1" cellspacing="0" bordercolor="#BBBBBB">
<tr bgcolor="#CCCCCC">
<th class="bold">COMPANY</th>
<th class="bold">APPOINTMENT STATUS</th>
<th class="bold">ISSUE DATE</th>
<th class="bold">CANCEL DATE</th>
</tr>
<tr bgcolor="#CDDEFF">
<td class="small">21ST CENTURY INSURANCE COMPANY </td>
<td class="small" style="color: GREEN"><b>ACTIVE</b> </td>
<td class="small">05/05/2006 </td>
<td class="small"> </td>
</tr>
<tr bgcolor="#EFEFEF">
<td class="small">AIG CENTENNIAL INSURANCE COMPANY </td>
<td class="small" style="color: GREEN"><b>ACTIVE</b> </td>
<td class="small">01/30/2008 </td>
<td class="small"> </td>
</tr>
<tr bgcolor="#CDDEFF">
<td class="small">BALBOA INSURANCE COMPANY </td>
<td class="small" style="color: RED"><b>INACTIVE</b> </td>
<td class="small">05/15/2006 </td>
<td class="small">04/23/2008 </td>
</tr>
</table>
<blockquote><img name="Image4" class="mouseover" onmouseover="this.style.cursor=" src="/MEDIA/images/gifs/squareminus.gif" onclick="visAction('Level4')" /> <b>
Use the extractor pattern below to match against the HTML above. It will return two results: 21ST CENTURY INSURANCE COMPANY, and AIG CENTENNIAL INSURANCE COMPANY, since those are the only two active company appointments. Note that the "Appointment" Extractor Pattern includes the word "GREEN", so that the "RED"(Inactive) company appointments are excluded.
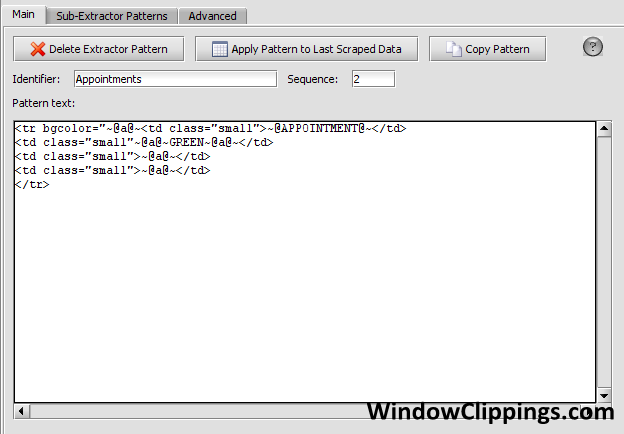
Be sure to check the box that says "This extractor pattern will be invoked manually from a script". This will ensure that the extractor pattern will not run in the sequence with the other extractor patterns.
<div id="Level2" style="Display: Block; position: relative; text-align: center">
<table class="verysmalltext" width="90%" border="1" cellpadding="1" cellspacing="0" bordercolor="#BBBBBB">
<tr bgcolor="#CCCCCC">
<th class="bold">ORIGINAL ISSUE DATE</th>
<th class="bold">DESCRIPTION</th>
<th class="bold">STATUS</th>
<th class="bold">EXPIRATION DATE</th>
<th class="bold">EXPIRATION REASON</th>
</tr>
<tr bgcolor="#CDDEFF">
<td>01/31/2006 </td>
<td>Agent - Property </td>
<td style="color: GREEN"><b>ACTIVE</b> </td>
<td> </td>
<td style='cursor:hand' onmouseover="this.style.cursor='pointer'" title='no information'><b style="color: #CA6C04"> </b></td>
</tr>
<tr bgcolor="#EFEFEF">
<td>01/31/2006 </td>
<td>Agent - Casualty </td>
<td style="color: GREEN"><b>ACTIVE</b> </td>
<td> </td>
<td style='cursor:hand' onmouseover="this.style.cursor='pointer'" title='no information'><b style="color: #CA6C04"> </b></td>
</tr>
</table>
</div>
<blockquote><img name="Image3" class="mouseover" onmouseover="this.style.cursor=" src="/MEDIA/images/gifs/squareminus.gif" onclick="visAction('Level3')" /> <b>COMPANY APPOINTMENTS</b></blockquote>
<div id="Level3" style="Display: Block; position: relative; text-align: center">
<table class="verysmalltext" width="90%" border="1" cellpadding="1" cellspacing="0" bordercolor="#BBBBBB">
<tr bgcolor="#CCCCCC">
<th class="bold">COMPANY</th>
<th class="bold">APPOINTMENT STATUS</th>
<th class="bold">ISSUE DATE</th>
<th class="bold">CANCEL DATE</th>
</tr>
<tr bgcolor="#CDDEFF">
<td class="small">21ST CENTURY INSURANCE COMPANY </td>
<td class="small" style="color: GREEN"><b>ACTIVE</b> </td>
<td class="small">05/05/2006 </td>
<td class="small"> </td>
</tr>
<tr bgcolor="#EFEFEF">
<td class="small">AIG CENTENNIAL INSURANCE COMPANY </td>
<td class="small" style="color: GREEN"><b>ACTIVE</b> </td>
<td class="small">01/30/2008 </td>
<td class="small"> </td>
</tr>
<tr bgcolor="#CDDEFF">
<td class="small">BALBOA INSURANCE COMPANY </td>
<td class="small" style="color: RED"><b>INACTIVE</b> </td>
<td class="small">05/15/2006 </td>
<td class="small">04/23/2008 </td>
</tr>
</table>
</div>
<blockquote><img name="Image4" class="mouseover" onmouseover="this.style.cursor=" src="/MEDIA/images/gifs/squareminus.gif" onclick="visAction('Level4')" /> <b>CONTINUING EDUCATION
Scrape Only Recent Information
This script is designed to check how recent a post or advertisement is. If you were gathering time sensitive information and only wanted to reach back a few days then this script would be handy. After evaluating the date there will be a section for calling other scripts from inside this script.
import java.util.Date;
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.lang.*;
import java.util.*;
import java.io.*;
// Function to parse the passed string into a date
makeDate(date)
{
//This is the format for your date. It is in the April 20, 1999 format
formatter = new SimpleDateFormat("MMM d, yyyy");
//some other options instead of blank could be null, N/A, etc. Really it just depends on how the site is structured.
if (date.equals("BLANK")){
session.log(" ---NO ATTEMPT TO PARSE BLANK DATE");
}
//if it is not blank go ahead and parse the data and apply the Format above. This will also print the date to the log.
else{
date = (Date)formatter.parse(date);
session.log(" +++Parsed date " + date);
}
return date;
}
// Function to get current date
oldestDate(){
// Set number of days to minus from current date.
minusDays = -5;
// Get the current date or instance, then you are going to add a negative amount of days. If that seems strange
// Just trust us. This is not a double negative thing.
Calendar rightNow = Calendar.getInstance();
rightNow.add( Calendar.DATE, minusDays );
// Substitute the Date variable endDate for rightNow becuase it makes more sense to
// Return endDate than a variable named rightNow which is 5 days in the past.
Date endDate = rightNow.getTime();
session.log("The end date is: " + endDate);
return endDate;
}
// Parse posted date. you are getting this posted date from a dataRecord.
// if you were getting it from a session variable it would say session.getVariable("POSTED_DATE")
posted = makeDate(dataRecord.get("POSTED_DATE"));
// Parse the current Date and return it in a format that you can compare to the advertisement or post date.
desired = oldestDate();
// Compare the two.<br />
if (posted.after(desired) || posted.equals(desired))
{
session.log ("AD IS FRESH. SCRAPING DETAILS.");
// If you are keeping track of URLs this will get it from the scrapeable file.
session.setVariable ("SOURCE_URL", scrapeableFile.getCurrentURL() );
// This is the place in the code where you would execute additional scripts.
session.executeScript("Your script name here");
session.executeScript("Your second script name here");
}
else{
session.log("Posted is too old");
}
Hopefully it is evident that the above code is useful in comparing todays date against a previous one. Depending on your needs you might consider developing a script which will move your scraping session on after it reaches a certain date in a listing. For example if you were scraping an auction website for many terms you might want to move on to the next term after you have reached a specified date for the listings. What are some other ways this script could be useful?