Extractor Tokens
Overview
Extractor tokens select the information from a file that you want to be able to access. The purpose of an extractor pattern is to give context to the extractor token(s) that it contains. This is to assist in getting the tokens to only return the information that you desire to have. Without extractor tokens you will not gather any information from the site.
Extractor tokens become available to dataRecord, dataSet, and session objects depending on their settings and the scope of the scripts invoked. All extractor tokens are surrounded by the delimiters ~@ and @~ (one for each side of the token). Between the two delimiters is where the name/identifier of the token is specified.
Managing Extractor Tokens
Adding
- Type ~@TOKEN_NAME@~ in the appropriate location in the Pattern text of the extractor or sub-extractor pattern.
Make appropriate changes to the TOKEN_NAME text to reflect the desired name of the token.
- Select a portion of the extractor pattern, right click, and select Generate extractor pattern token from selected text
Removing
- Remove the token and delimiters from the Pattern text of the extractor pattern like you would with any text editor
Editing
- Double-click on the desired extractor token's name
- Select the extractor token's name, right click, and choose Edit token
Extractor Token: General tab
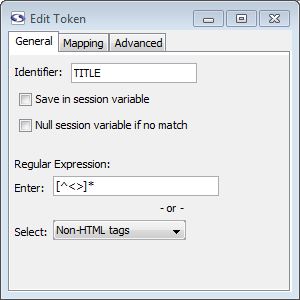
General Tab
- Identifier: This is a string that will be used to identify the piece of data that gets extracted as a result of this token. You can use only alphanumeric characters and underscores here.
- Save in session variable: Checking this box causes the value extracted by the token to be saved in a session variable using the token's identifier.
- Null session variable if no match (enterprise edition only): When checked, if a session variable was matched previously but not this time, the value will be set to null. If unchecked the unmatched token would do nothing to the session variable so that the old session variable persists.
- Regular Expression: Here you can designate a regular expression that will be used to match the text covered by this token. In most cases you should designate a regular expression for tokens. This makes the extraction more efficient and helps to guard against future changes that might be made to the target web site.
- Enter: Type in your own regular expression.
- Select: Select a predefined regular expression by name.
The regular expressions that appear in the drop-down list can be edited by selecting Edit regular expressions from the menu.
Extractor Token: Mapping tab
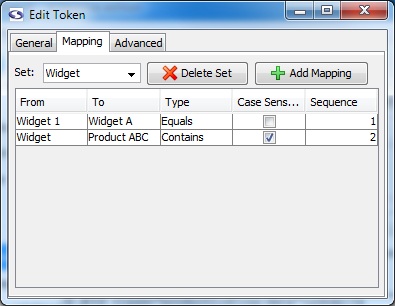
Mapping Tab (enterprise edition only)
We would encourage you to read our documentation on mapping extracted data before you start using mappings.
- Set (enterprise edition only): Name of the mapping group.
To create a new set, select the text in the Set textbox and start typing the name of the new set.
- Delete Set (enterprise edition only): Deletes the currently selected set.
- Add Mapping (enterprise edition only): Adds a mapping to the currently selected set.
- From: The value screen-scraper should match.
- To: Once a match is found, indicates the new value the extracted data will assume.
- Type: Determines the type of match that should be made in working with the value in the From field. The Equals option will match if an exact match is found, the Contains value will match if the value contains the text in the From field, and the regular expression type uses the From value as a regular expression to attempt to find a match (see regular expression help for more information on regular expressions).
- Case Sensitive: Indicates whether or not the match should be case sensitive.
- Sequence: Determines the sequence in which the particular mapping should be analyzed.
Mappings can be deleted by pressing the Delete key on your keyboard after selecting them.
Extractor Token: Advanced tab
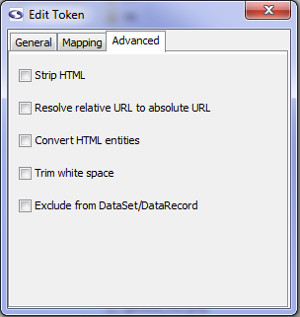
Advanced Tab (enterprise edition only)
- Strip HTML (enterprise edition only): Check this box if you'd like screen-scraper to pull out HTML tags from the extracted value.
- Resolve relatively URL to absolute URL (enterprise edition only): If checked, this will resolve a relative URL (e.g., /myimage.gif) into an absolute URL (e.g., http://www.mysite.com/myimage.gif).
- Convert HTML entities (enterprise edition only): This will cause any html entities to be converted into plain text (e.g., it will convert & into &).
- Trim white space (enterprise edition only): This will cause any white space characters (e.g., space, tab, return) to be removed from the start and end of the matched string.
- Exclude from DataSet/DataRecord (enterprise edition only): This will cause this token to not be saved in the DataRecord from each match of the extractor pattern